Today we’ll analyze a million eHarmony couples, each a male and a female [1] matched by eHarmony’s algorithm. We know everything from how passionate, intelligent, and ambitious our lovers claim to be to how much they drink and smoke to their preferences in other people and (the good part) whether the male contacted the female within a week and vice versa. This is a total of 204 facts about each couple, making the data too rich and complex to understand in a single analysis: consider this a first date with the data.
Actually, this metaphor’s appropriate: though sipping Amarone by candlelight bears little resemblance to running regressions, you’d be surprised at the similarities between first meeting a dataset and first meeting a date. You’re given the opportunity to discover wonderful secrets about the creature in front of you, if you can manage a paradox of patience and pushiness. On the one hand, you have to be gentle: you have to listen to what they’re trying to tell you, you can’t force your preconceptions on them. On the other, you have to be bold: you have to ask the questions you’re interested in, and follow your heart about what matters. In both dating and data, all the technical virtuosity in the world -- insincere flirtation, unnecessary real analysis -- won’t get you anywhere without empathy and passion. And there are raunchier parallels as well: both may require you to stay up late, strip away outer layers, and bring a computer cord to bed [2].
Now that I’ve convinced you of my ignorance of both love and statistics, let’s talk about the statistics of love. I’m going to focus on a simple question: how are men and women different?
Who’s pickier? Complicated. Short answer: women claim to be pickier, eHarmony ignores them, and then they take what they’re given anyway.
Women express stronger preferences about their date along every dimension. Below, I rank all preferences sorted by how much more important they were to women than men (on a scale of 1-6).
Trait
|
Average Strength of Preference (women)
|
Average Strength of Preference (men)
|
Women - Men
|
Height
|
4.7
|
3.0
|
1.7
|
Income
|
4.6
|
3.0
|
1.6
|
Education
|
4.8
|
3.6
|
1.2
|
Drinking level
|
4.5
|
3.5
|
1.0
|
Religion
|
4.2
|
3.3
|
0.9
|
Ethnicity
|
4.6
|
3.8
|
0.8
|
Smoking Level
|
5.4
|
4.7
|
0.7
|
Age
|
4.8
|
4.2
|
0.6
|
Distance
|
4.9
|
4.6
|
0.3
|
So the women express stronger preferences, which apparently annoys eHarmony’s matching algorithm: 69% of men have their preferences satisfied by the algorithm’s matches, whereas only 60% of women do. (Of course, I’m sure eHarmony doesn’t discriminate against women; it’s just harder to satisfy them.) Here’s the weird part: even though they’re less often satisfied, women still contact their matches at higher rates. I guess we’re just inured to disappointment.
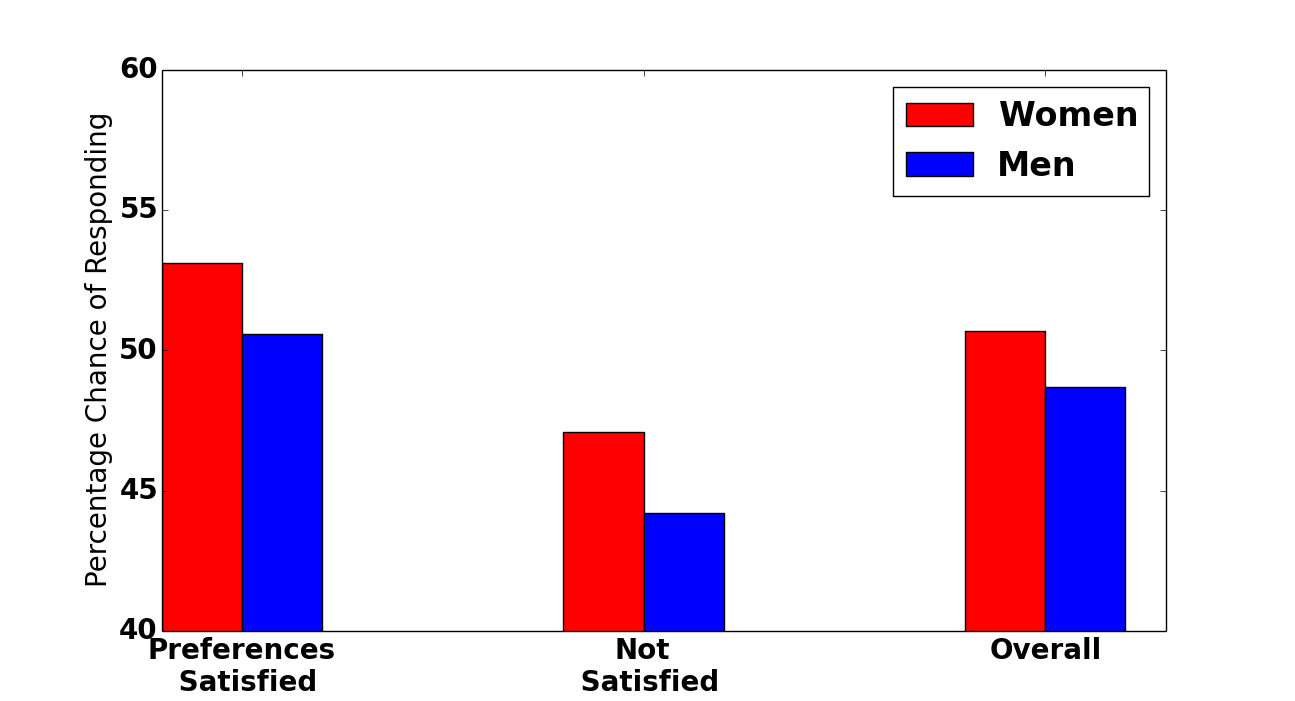
Alternately, it could be because there are more women than men on eHarmony: roughly 53% of the unique ids are female, which is more dramatic than the skew in acceptance rates (51% to 49%). So given their numbers advantage, guys may actually be selling themselves slightly short.
How do men and women describe themselves differently?
We can plot the frequency with which men and women use certain adjectives to describe themselves. Words above the line are more commonly used by men, and words below the line by women.
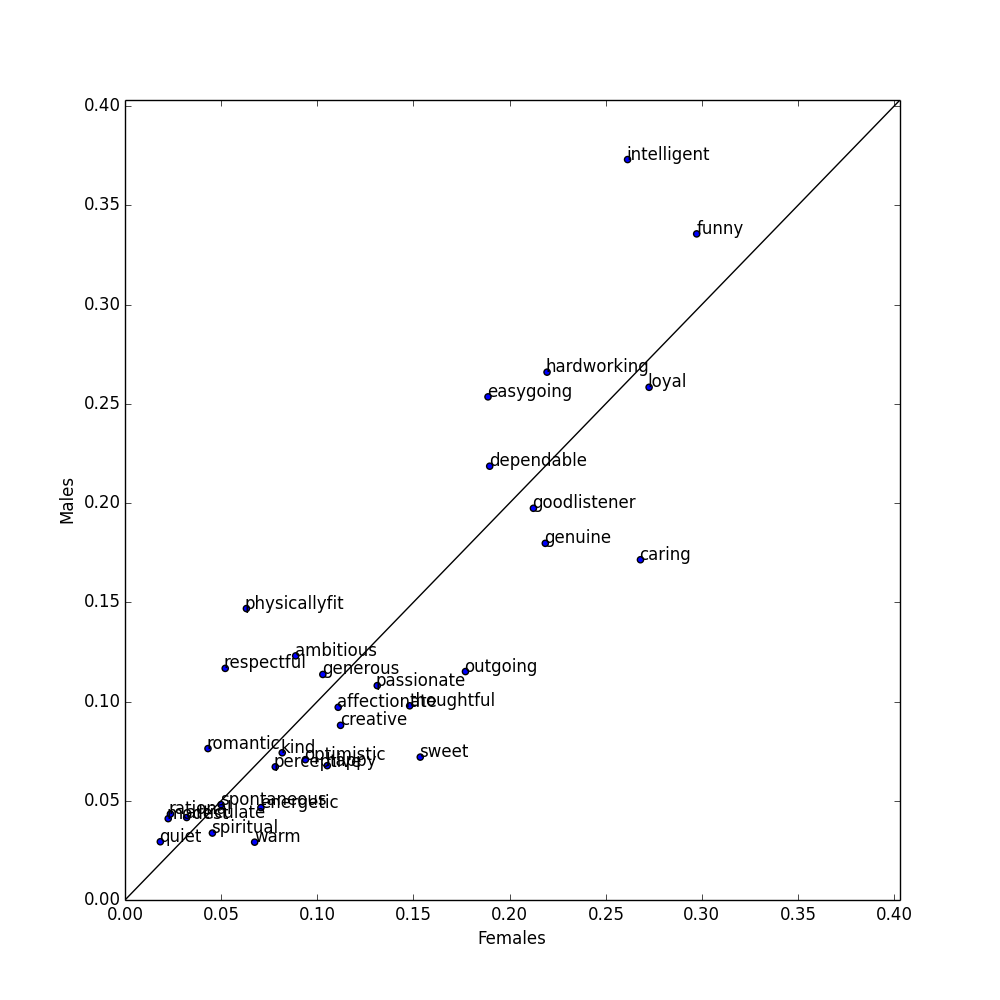
Words used more by men
|
Words used more by women
|
1. Intelligent (37.3% vs 26.1%)
|
1. Caring (26.7% vs 17.2%)
|
2. Physically fit (14.7% vs. 6.3%)
|
2. Sweet (15.3% vs 7.2%)
|
3. Easygoing (25.4% vs 18.9%)
|
3. Outgoing (17.7% vs 11.5%)
|
4. Respectful (11.7% vs 5.2%)
|
4. Thoughtful (26.8% vs 17.1%)
|
5. Hardworking (11.7% vs 5.2%)
|
5. Genuine (21.9% vs 18.0%)
|
You might expect that the adjectives people use to describe themselves are the ones likely to get them responses [3]. This turns out not to be the case: there’s no significant correlation between how often a gender uses an adjective and how often people who use that adjective get responses. In general, the adjectives you use don’t seem to make a big difference (come on -- it’s not your personality I’m interested in) but there are a few notable exceptions that I’ll disclose for the benefit of your love lives:
Sexier for women
|
Both “physically fit” and “sweet” are more likely to get you a date as a woman than a man. But women use “physically fit” about 8% less than men, and use “sweet” about 8% more.
|
Sexier for men
|
“Spiritual” is about 8% more likely to get you a date as a man than a woman.
|
Bad for both
|
“Quiet”. Don’t use this word. It’s the least sexy for both sexes, and particularly bad for men.
|
Overused
|
Both sexes use “intelligent” and “funny” frequently, but neither word is particularly good at getting them dates. My guess would be that this is because they’re generic.
|
Of course, men and women differ in many other ways in terms of what they want in a mate. Attractiveness matters more for women; on the x-axis I plot attractiveness for both men and women, and on the y-axis how likely they are to get a response.
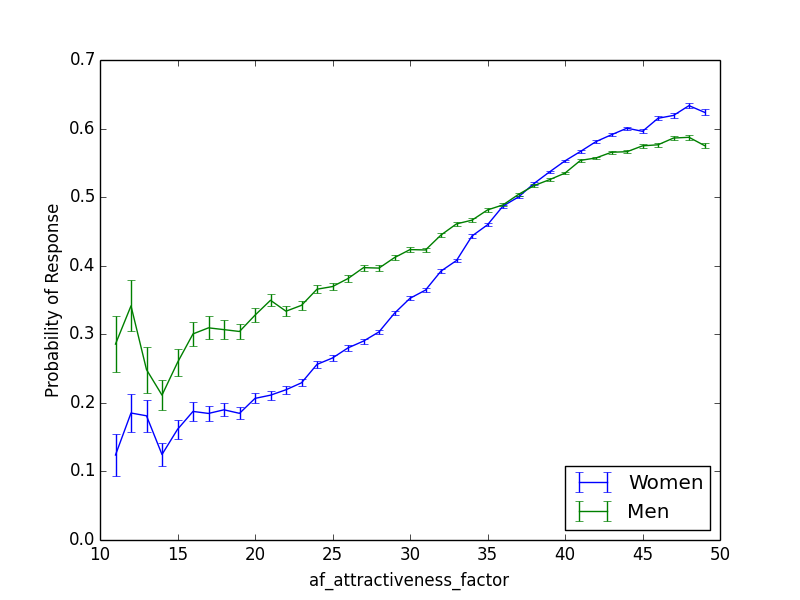
And age has pretty much opposite effects. 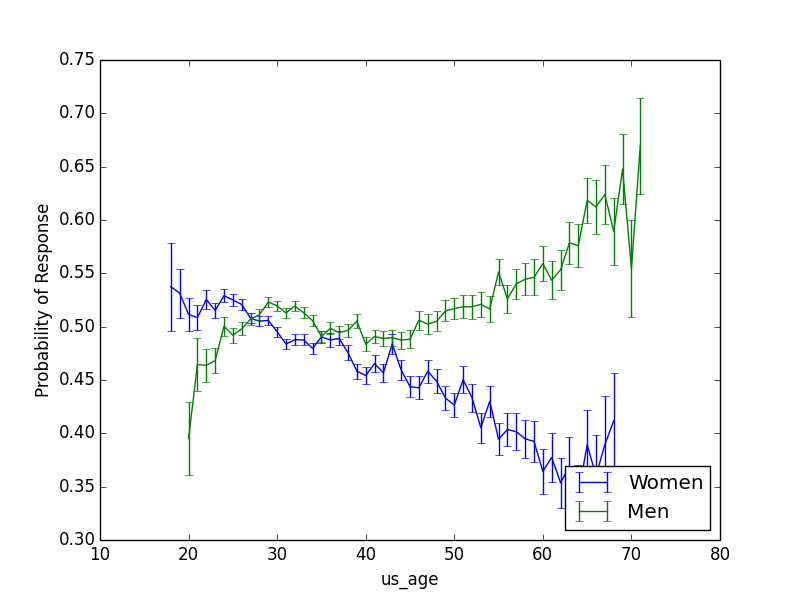
I thought older women might do worse in part because they outnumbered older men (because women live longer). But in fact the reverse is true: as the age of users increases, the fraction of females decreases, and the majority of people over 60 on the site are males. It’s just really hard to get a date on a dating site if you’re an older woman: this a depressing phenomenon has been thoroughly explored in this lovely post.
For men, being taller is pretty much always better, but women over 5’ 7” should consider kneeling.
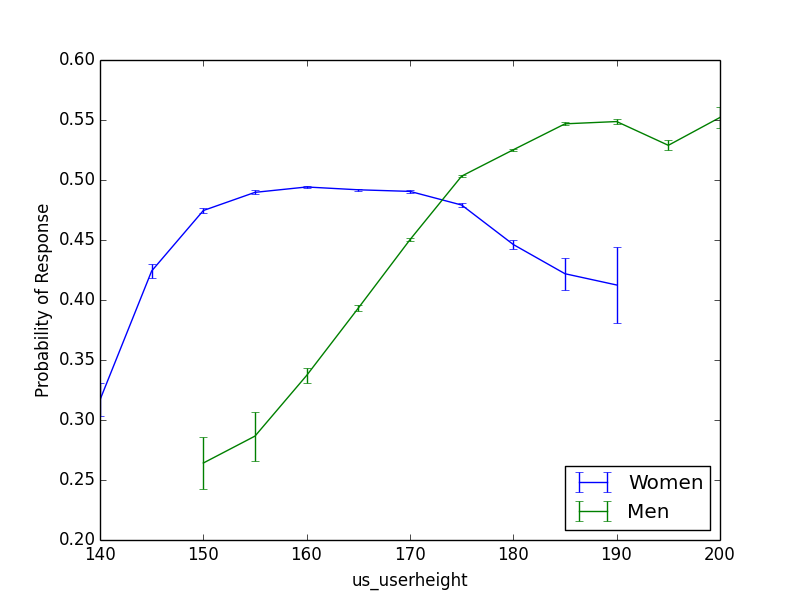
Other interesting sex differences:
Marital status: For a man, being divorced is slightly less sexy than being widowed, but for a woman, being widowed is way worse. A widowed man has a 54% chance of getting a response; a widowed woman, 37%.
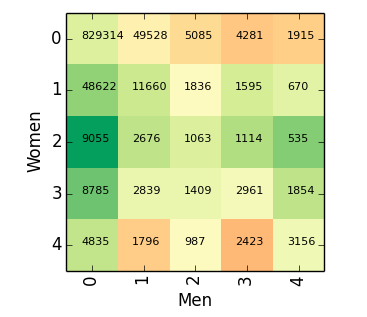
Smoking: Men's sexiness decreases with the amount they smoke, but women are actually most likely to be asked out if they say they smoke “occasionally”. I was taken aback by this, and thought it might just be because male smokers get paired with female smokers, and male smokers find it harder to get a date, so they just ask everyone out. But, no -- men are more likely to ask out women who smoke regardless of whether they themselves do [4]. In the plot below, the color of a square indicates how likely the man is to ask the woman out (green = more likely), and the position indicates how much the man and woman smoke. (The number is just how many datapoints we have.) You can see that the row labeled “2” for women, indicating women who smoke "occasionally", beats all the other rows regardless of how much the man smokes.
Keep an eye out for the next eHarmony post, in which we’ll examine whether opposites really attract and learn about the four types of lovers. This is such a great dataset that you could keep going all night...but one should leave something for the second date.
Notes:
[1] Yes, I also think it’s weird and bad that the dataset includes only heterosexual couples. Let me know if you have a good same-sex dataset.
[2] Jokes!
[3] Because that’s the true parallel between love and statistics: in both, you bend the truth to get what you want.
[4] All this proves is that women have better taste than men; please please please don’t smoke.