This is the second half of a two-part piece about arguments I’ve had with Shengwu Li. Part 1 gives a statistical argument for why in some states it is rational to vote.
Today’s question: can you sleep through the first round of a 9-round debate tournament, like the World or European championships, without hurting your final result? You might think this question is only interesting to debaters, but the mathematical way of answering it is potentially applicable to any tournament with some randomness in pairings in which the winners play the winners and the losers play the losers; this also happens in chess and lots of other competitions.
(Brief note for non-debaters: in each round of the debate world championships, you compete against three other teams, earn up to three points, want to accumulate as many points as possible. In each round, you’re paired against teams with roughly the same number of points, so if you win, you face better teams.)
The argument that the first round doesn’t matter is that, if you lose, you face worse teams in the next eight rounds, an advantage you can capitalize on. Perhaps this evens out.
A first glance at the data would imply this argument is wrong. In the three debate world championships from 2013 - 2015, teams who earned three points in their first round ended up with about six more points by the end of the tournament than teams who earned zero points in their first round. This seems pretty amazing, because you only get three points from winning your first round, and then you have to face better teams; how do you end up six points better? Perhaps winning your first round gives you a confidence boost that improves your performance?
This reasoning is wrong. Winning your first round doesn’t necessarily cause you to do better in later rounds; it’s just a sign you’re a better team. (Similarly, getting in an ambulance doesn’t cause you to die; it’s just a sign that you’re sick.) The teams who win their first rounds would’ve done better whether they won their first rounds or not.
If we want to figure out whether winning your first round causes you to do better overall, we need to control for the fact that teams that win their first rounds are better. In an ideal world, we’d just do an experiment: instead of running the first round, we’d divide teams into four random, equally-sized groups, give one group 3 points, one group 2 points, one group 1 point, and one group 0 points, run the rest of the tournament normally, and see whether the initial advantage ended up mattering. But we can’t run a real random experiment, so we need to find a random factor that affects who wins the first round. We call the random factor an instrumental variable. The math behind how exactly this works is beyond the scope of the post (here’s a less mathy reference, here’s a more mathy one), but the basic recipe is straightforward. If you want to know how cause X affects outcome Y, you need to find a random factor Z which affects X (and is uncorrelated with Y when controlling for X). Then there’s some math that lets you put those three ingredients together to figure out how X affects Y. That’s a lot of symbols, so here are some examples.
How does X...
|
Affect Y...
|
Random factor Z which affects X
|
Reference
|
Serving in the Vietnam War
|
Future earnings
|
Draft lottery number
| |
Tea party protests
|
Election outcomes
|
Rain on tax day
| |
Iron metabolism
|
Risk of Parkinson’s
|
Genetic variants affecting iron metabolism
| |
Height and BMI
|
Socioeconomic status
|
Genetic variants affecting height and BMI
|
To return to our debate problem: our X is how well you do in round 1, our outcome Y is how well you do in the tournament overall, and now we need a random factor Z that affects how well you do in round 1. One random factor that affects a team’s probability of winning round 1 is how good the other teams in the round are, since teams are randomly matched in the first round. We estimate the likelihood that each team will win the round using a number of other factors, including their record in past tournaments, their school’s record in past tournaments, and their EFL / ESL status [1], and use these as our instruments. Then we use these instruments to estimate the true causal effect of winning round 1. (Another source of randomness you could potentially use is which position you’re assigned to; we discuss this further here [2]).
Here are the results. The red line shows the estimated effect of your round one result on your score after each round (x-axis) using the naive, incorrect method we describe above; the black line shows the estimated effect using the more sophisticated instrumental variable method.
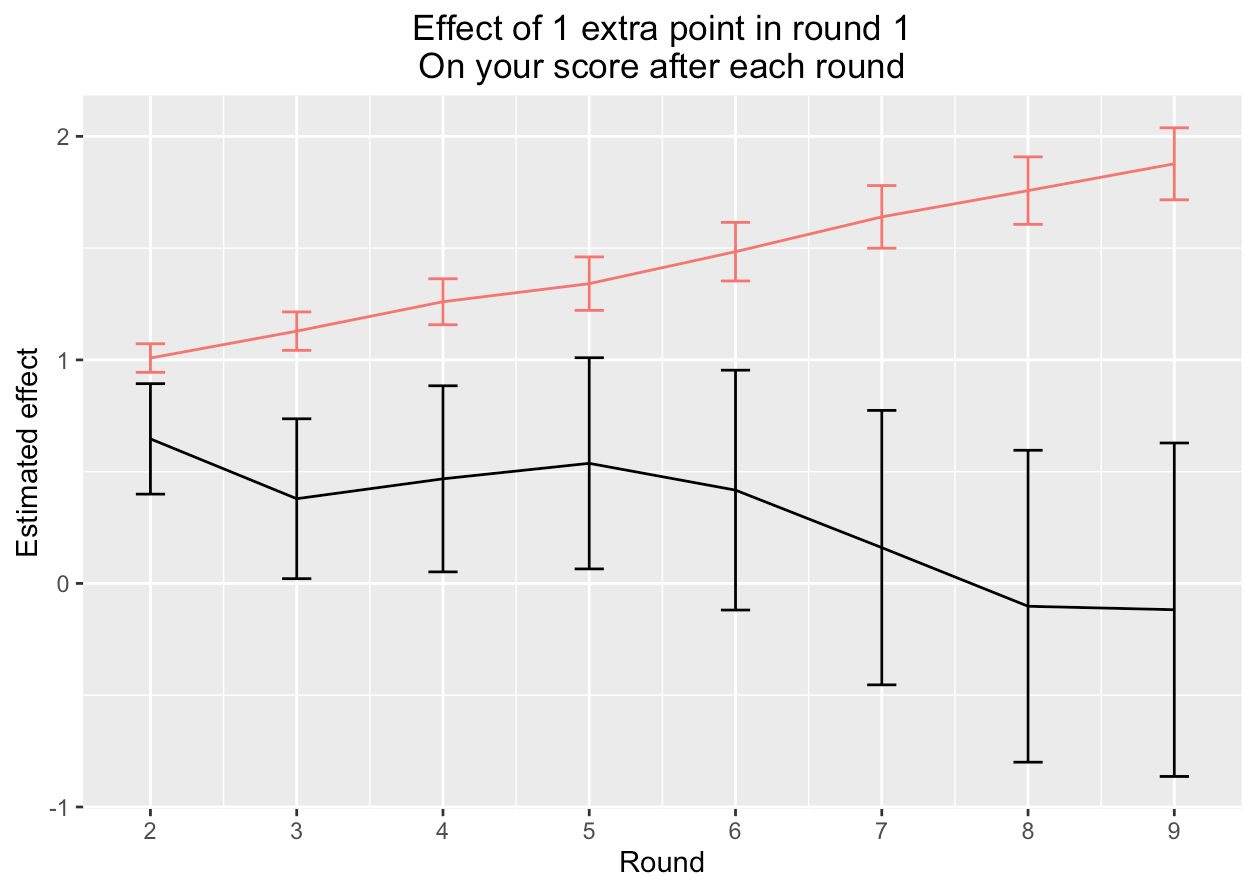
A couple interesting things here. First, the red line and the black line are very different; in particular, the naive approach (red line) suggests that winning round 1 has a much larger effect, and this gets bigger as the tournament progresses, which is wrong for the reasons discussed above. The more sophisticated analysis implies that while winning round 1 affects your performance for a couple rounds, by the end of the tournament (round 9) it doesn’t make much difference. (The 95% confidence interval on the estimate is unfortunately large [3], because the instruments aren’t that strong.)
Takeaways:
- Don’t freak out too much if you do badly in an early round in a long tournament like Worlds or Euros -- our estimates suggest it doesn’t affect your final performance very much, if at all. On the other hand, in shorter 4 - 6 round tournaments, losing an early round can have a larger effect.
- If early rounds have a smaller effect on your final performance, it might be better to run controversial debates in earlier rounds; that way if teams had to opt out, they could do so without taking as large a hit to their final result.
- Storing comprehensive data from all Worlds in a single centralized repository, with a standard format, would make these analyses easier and is worth doing.
- Naive correlational estimates of effects are often different than those estimated using causal methods. For the love of God, bear this in mind when reading popular social science coverage. Even if the authors claim to have “controlled for other factors”, this phrase does not work magic. It is very difficult to control completely for other factors.
Notes:
[1] This isn’t, of course, a perfect measure of team strength -- since Oxford A is usually composed of different people from year to year, and many teams do not appear in other Worlds.
[2] In each round, every team will debate the same statement -- for example, “We should ban abortions at all stages of pregnancy” -- but because there are four teams in the same room, two teams will be randomly assigned to argue for the statement, and two teams will be assigned to argue against the statement. It’s hard to come up with statements which are perfectly balanced, so it’s often better to be on one side or the other. We found that a team’s score after the first four rounds was significantly associated with the positions they had been randomly assigned in those rounds, so position in the first four rounds could be used as an instrument. You have to use the first four rounds, not just the first round, to satisfy the exclusion restriction, since most debate teams cycle through all four positions in the first four rounds.
[3] I think you should actually compute standard errors clustering by round, since results within round are highly correlated; when you do this, the errorbars are slightly larger but the conclusions are the same.