This is the second half of a two-part piece about arguments I’ve had with Shengwu Li. Part 1 gives a statistical argument for why in some states it is rational to vote.
Today’s question: can you sleep through the first round of a 9-round debate tournament, like the World or European championships, without hurting your final result? You might think this question is only interesting to debaters, but the mathematical way of answering it is potentially applicable to any tournament with some randomness in pairings in which the winners play the winners and the losers play the losers; this also happens in chess and lots of other competitions.
(Brief note for non-debaters: in each round of the debate world championships, you compete against three other teams, earn up to three points, want to accumulate as many points as possible. In each round, you’re paired against teams with roughly the same number of points, so if you win, you face better teams.)
The argument that the first round doesn’t matter is that, if you lose, you face worse teams in the next eight rounds, an advantage you can capitalize on. Perhaps this evens out.
A first glance at the data would imply this argument is wrong. In the three debate world championships from 2013 - 2015, teams who earned three points in their first round ended up with about six more points by the end of the tournament than teams who earned zero points in their first round. This seems pretty amazing, because you only get three points from winning your first round, and then you have to face better teams; how do you end up six points better? Perhaps winning your first round gives you a confidence boost that improves your performance?
This reasoning is wrong. Winning your first round doesn’t necessarily cause you to do better in later rounds; it’s just a sign you’re a better team. (Similarly, getting in an ambulance doesn’t cause you to die; it’s just a sign that you’re sick.) The teams who win their first rounds would’ve done better whether they won their first rounds or not.
If we want to figure out whether winning your first round causes you to do better overall, we need to control for the fact that teams that win their first rounds are better. In an ideal world, we’d just do an experiment: instead of running the first round, we’d divide teams into four random, equally-sized groups, give one group 3 points, one group 2 points, one group 1 point, and one group 0 points, run the rest of the tournament normally, and see whether the initial advantage ended up mattering. But we can’t run a real random experiment, so we need to find a random factor that affects who wins the first round. We call the random factor an instrumental variable. The math behind how exactly this works is beyond the scope of the post (here’s a less mathy reference, here’s a more mathy one), but the basic recipe is straightforward. If you want to know how cause X affects outcome Y, you need to find a random factor Z which affects X (and is uncorrelated with Y when controlling for X). Then there’s some math that lets you put those three ingredients together to figure out how X affects Y. That’s a lot of symbols, so here are some examples.
How does X...
|
Affect Y...
|
Random factor Z which affects X
|
Reference
|
Serving in the Vietnam War
|
Future earnings
|
Draft lottery number
| |
Tea party protests
|
Election outcomes
|
Rain on tax day
| |
Iron metabolism
|
Risk of Parkinson’s
|
Genetic variants affecting iron metabolism
| |
Height and BMI
|
Socioeconomic status
|
Genetic variants affecting height and BMI
|
To return to our debate problem: our X is how well you do in round 1, our outcome Y is how well you do in the tournament overall, and now we need a random factor Z that affects how well you do in round 1. One random factor that affects a team’s probability of winning round 1 is how good the other teams in the round are, since teams are randomly matched in the first round. We estimate the likelihood that each team will win the round using a number of other factors, including their record in past tournaments, their school’s record in past tournaments, and their EFL / ESL status [1], and use these as our instruments. Then we use these instruments to estimate the true causal effect of winning round 1. (Another source of randomness you could potentially use is which position you’re assigned to; we discuss this further here [2]).
Here are the results. The red line shows the estimated effect of your round one result on your score after each round (x-axis) using the naive, incorrect method we describe above; the black line shows the estimated effect using the more sophisticated instrumental variable method.
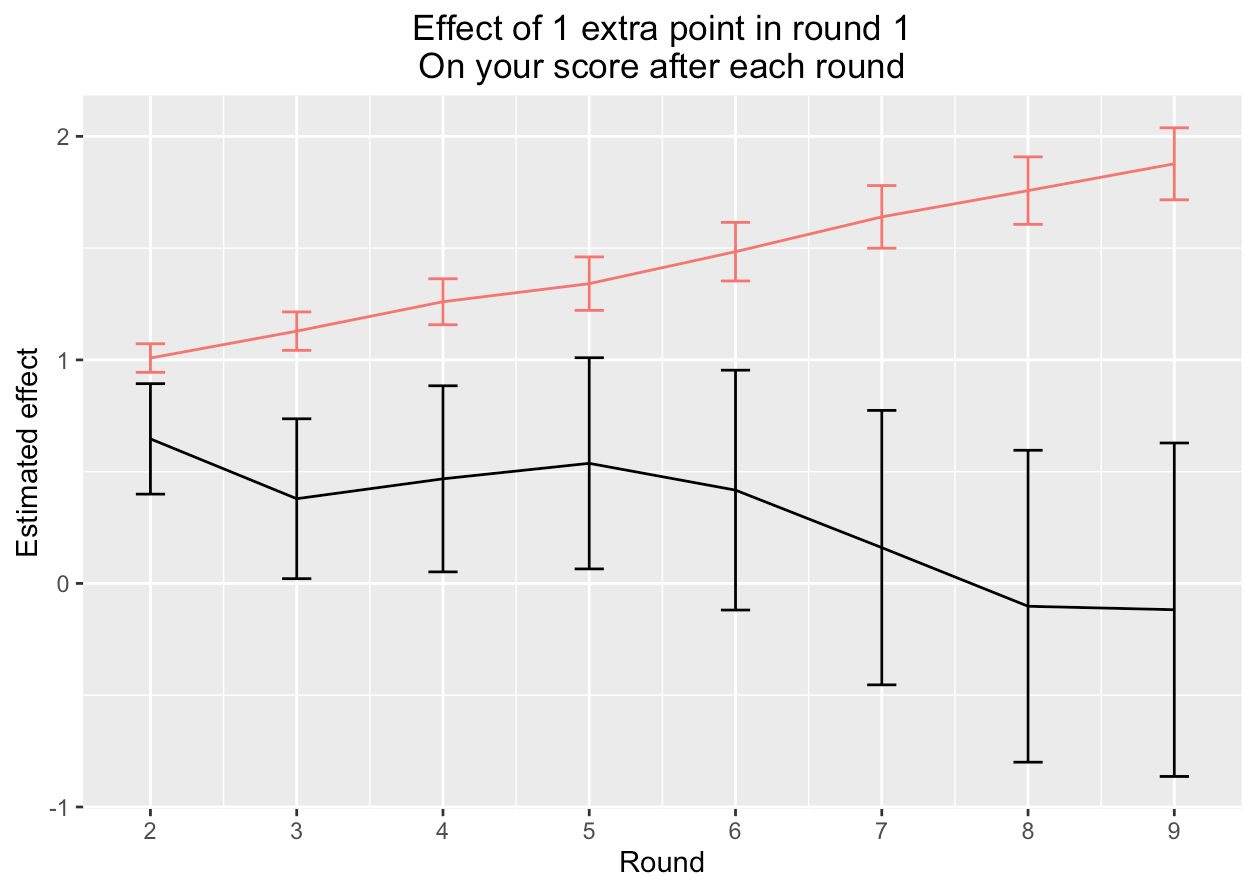
A couple interesting things here. First, the red line and the black line are very different; in particular, the naive approach (red line) suggests that winning round 1 has a much larger effect, and this gets bigger as the tournament progresses, which is wrong for the reasons discussed above. The more sophisticated analysis implies that while winning round 1 affects your performance for a couple rounds, by the end of the tournament (round 9) it doesn’t make much difference. (The 95% confidence interval on the estimate is unfortunately large [3], because the instruments aren’t that strong.)
Takeaways:
- Don’t freak out too much if you do badly in an early round in a long tournament like Worlds or Euros -- our estimates suggest it doesn’t affect your final performance very much, if at all. On the other hand, in shorter 4 - 6 round tournaments, losing an early round can have a larger effect.
- If early rounds have a smaller effect on your final performance, it might be better to run controversial debates in earlier rounds; that way if teams had to opt out, they could do so without taking as large a hit to their final result.
- Storing comprehensive data from all Worlds in a single centralized repository, with a standard format, would make these analyses easier and is worth doing.
- Naive correlational estimates of effects are often different than those estimated using causal methods. For the love of God, bear this in mind when reading popular social science coverage. Even if the authors claim to have “controlled for other factors”, this phrase does not work magic. It is very difficult to control completely for other factors.
Notes:
[1] This isn’t, of course, a perfect measure of team strength -- since Oxford A is usually composed of different people from year to year, and many teams do not appear in other Worlds.
[2] In each round, every team will debate the same statement -- for example, “We should ban abortions at all stages of pregnancy” -- but because there are four teams in the same room, two teams will be randomly assigned to argue for the statement, and two teams will be assigned to argue against the statement. It’s hard to come up with statements which are perfectly balanced, so it’s often better to be on one side or the other. We found that a team’s score after the first four rounds was significantly associated with the positions they had been randomly assigned in those rounds, so position in the first four rounds could be used as an instrument. You have to use the first four rounds, not just the first round, to satisfy the exclusion restriction, since most debate teams cycle through all four positions in the first four rounds.
[3] I think you should actually compute standard errors clustering by round, since results within round are highly correlated; when you do this, the errorbars are slightly larger but the conclusions are the same.
View here pro-academic-writers.com best writing tips.
ReplyDeleteAs opposed to quickest-finger-first to fill this workshop, we've got determined to mild attendees. To register your interest, please rsvp for the waiting listing with a paragraph reaction to the questions "How do you technique regression testing on your enterprise? Question shared by Intelligentessays.com
ReplyDeleteTiers of sleep and sleep cycles. Commonly sleepers bypass thru four stages: 1, 2, three, and rem (speedy eye motion) sleep. Those ranges progress cyclically from 1 thru rem then begin once more with degree 1. A complete sleep cycle takes an average of 90 to a hundred and ten mins, with each stage lasting between five to 15 mins. Info delivered by Do My Assignment for Me Cheap - All Assignment Help.
ReplyDeleteLooking great work dear. These tips may help me in the future. If you are looking for help with game theory assignment and meet the requirement before the deadline, then you are at the right place. Avail the Nursing Assignment Help service from GoAssignmentHelp Portal.
ReplyDeleteThanks for sharing such a nice Blog.I like it.
ReplyDeleteactivate my norton antivirus
norton product key
mcafee antivirus activation key
comcast support telephone number
avg antivirus tech support phone number
webroot contact number
kaspersky support phone number
Outlook helpline number
microsoft edge support number
AbikoOnline Daraz
ReplyDeleteSchauffele shot the pleasant score by using two strokes, however, my sleeper pick, Hideki Matsuyama, shot a sixty-six and is in high function to make a circulate on Friday and Saturday.
ReplyDeleteSource by Cheap Essay Writing Services | 6DollarEssay.
At our CheapEssay writing provider, that has been in the commercial enterprise of writing instructional works for students for decades, and know nicely all of the intricacies of this enterprise. You may make sure that whoever is assigned to jot down your particular assignment at our service, the results are going to be outstanding.
ReplyDeleteYou could make sure that whoever is assigned to jot down your unique project at our service, the outcomes are going to be remarkable. In preference to fastest-finger-first to fill this workshop, we've got were given decided to mild attendees. Cheap Essay Writing
ReplyDeleteCall now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280
ReplyDeleteIf you professor ordered you to write argumentative essay on school uniforms you need to check out this blog post. I think that this kind of info could be useful
ReplyDeleteThe present inquiry would you be able to rest through the first round of a 9-round discussion competition, similar to the World or European titles, without harming your conclusive outcome? You may think this inquiry is just fascinating to debaters, however the numerical method for noting it is possibly pertinent to any competition with some arbitrariness in pairings in which the victors play the champs and the failures play the washouts; this likewise occurs in chess and heaps of different rivalries.
ReplyDeleteBest Content Writing Services
I'm looking senior project examples. I do not write the essay myself. I use additional information. I order an essay on any subject. I can save my time.
ReplyDeleteMy Silver Service hopes that by giving all customers the best service possible, and My silver Service can encourage repeat business as well as referral to friends and family and good reviews.
ReplyDeletetaxi melbourne baby seat
We do your online class as we offer quality online class help and we are best if you’re searching to take my online class for me or Pay To Take My Online Class For Me!
ReplyDeleteOur Academic papers may be done as a part of a class, in a program of your study. We design our academic writing service in literary analysis, research paper and dissertation.
ReplyDeleteEssay
At last my enthusiasm lies in inventive articulation through composition and showing others how its done to help other people along their way of self-revelation.
ReplyDeletewhiteboard animation video
For those who want Government Jobs Latest Update and news, this is the website to come. You can check here for the latest updates about govt job. On this website you can found All India Govt Jobs Employment News of Central and State Government Jobs, Govt Undertaking, Public Sector, Railway and Bank Jobs In India.
ReplyDeleteArmy Recruitment
Railway Jobs
Jobs in India
Teaching Jobs
Engineering Jobs
Bank Jobs in India
State Government Jobs
trung tâm tư vấn du học canada vnsava
ReplyDeletecông ty tư vấn du học canada vnsava
trung tâm tư vấn du học canada vnsava uy tín
công ty tư vấn du học canada vnsava uy tín
trung tâm tư vấn du học canada vnsava tại tphcm
công ty tư vấn du học canada vnsava tại tphcm
điều kiện du học canada vnsava
chi phí du học canada vnsava
#vnsava
@vnsava
Do you want online exam help? All you have got to say is do my online exam for me. We provide the best take my online exam help.
ReplyDeleteWeb Design Services in USA offers custom web design for home service companies. Our contractor websites generate more leads and sales, guaranteed!
ReplyDeletegoogle 3440
ReplyDeletegoogle 3441
google 3442
google 3443
google 3444
google 232
ReplyDeletegoogle 233
google 234
google 235
google 236
google 237
google 238
Get Custom Dissertation Writing Services UK by professional dissertation writers. UK Diss Get discount on all your dissertation writing help orders today!
ReplyDeletegoogle 3399
ReplyDeletegoogle 3400
google 3401
google 3402
google 3403
google 3404
Premium Brand Designs is the best https://premiumbranddesigns.com/logo-design.php that serves you at cheap prices while maintaining top quality.
ReplyDeleteDon’t worry and just subscribe to our Best Logo Design Company in USA who is eager to help you in all the aspects of designing.
ReplyDeleteI want to testify on how I got cured from Herpes. I have been living with this disease for the past 11 months, i have done all i can to cure this disease but all my efforts proved abortive until i met an old friend of mine who told me about a herbal doctor called Dr Oniha, she told me that Dr Oniha have cure for all kinds of diseases, though i never believed in it because my believe was that there is no cure for Herpes disease. But I decided to give it a try when I contacted Dr Oniha, he told me he has a cure for herpes that he cured with herbal medicine. I order for the herbal medicine, which Dr Oniha sent to me through a courier service which i make use of and now behold the herpes is gone and i now have my life back,if you are out there living with this disease i will like you to also contact Dr Oniha and get this disease cured out of your body. I am a living testimony of Dr Oniha herbal cure. Thanks once again Dr Oniha for you are God sent. contact Dr oniha through his contact information.
ReplyDeleteEmail:driyaseherblahoe@gmail.com
Whatsapp number: +2347057052206
Hire Someone To Take My Class? Reach out to take my online class for me. We have the best online class Helper to your Take Your Online class for my needs.
ReplyDeleteWe assure you that you will get impressive scores in your course!
ReplyDeleteNeed take my online class services? Reach out to Online Class Help Now. We have the best online class takers to help your Do My Course Online For Me needs.
ReplyDeleteOur online course experts will assist you topics in all areas like hire someone to take a test.
ReplyDeleteYour article is very useful, the content is great, I have read a lot of articles, but for your article, it left me a deep impression, thank you for sharing. for More Information Click Here:- HP Support Assistant
ReplyDeleteThe reel n realtor well leading real estate company in south Florida. They have highly trained Real Estate Experts that help you to purchase and buy property.
ReplyDeleteambbet เว็บไซต์ที่รวบรวมข่าวสารวงการเกมเดิมพันออนไลน์ เเชร์สูตรสล็อต ทรคิ เเบะเทคนิคในการทำเงินของเกเมดิมพันออนไลน์ สล็อตออนไลน์ไว้ในเว็บไซต์เดียว คลิกตรงนี้ สูตรสล็อตออนไลน์ แฮ็กสล็อต ใช้ได้ทุกเกม ใช้ได้ทุกเว็บไซต์ ให้อ่าน เเจกเเบบฟรีๆ ไม่มีค่าช้จ่ายใดๆ ทั้งสิ้น รับรองว่าสามารถทำเงินได้อย่างต่อเนื่อง เเละปังอย่างเเน่นอน !!
ReplyDeleteโอเคนอน
ReplyDeletepg slot zone
อย่าทำเก็ก
ReplyDeleteJOKER GAMING โจ๊กเกอร์สล็อต
ReplyDeleteLucassalon is one of the Top Hair salons in Hyderabad . We provide services-
Hair Volume treatment in Hyderabad
Best Hair colour Salon in Hyderabad
French Balayage Hair Colour in Hyderabad ,Keratin treatment in Hyderabad and more.
Do you need a Pest Control KL ? Mypestcontrol provides the most effective pest control available in KL. Our solutions are highly effective, kid and pet-friendly and completely eco-friendly.
ReplyDeleteIf you are looking for Monmouth Car service that will relocate your car from one destination to another in a safe and secured way, then Welimos will help you to get the right car services in Monmouth for your car shifting.
ReplyDeleteWe offer stylish nautical lamps,Pelican lamps,
ReplyDelete,Turtle Lamp,Coastal Lamps,& Mermaid Lamps a wide variety of styles, colors, and shapes to suit your budget and needs.
อยู่กับฉันอีกครั้ง สล็อต เว็บ ใหญ่ ที่สุด pg
ReplyDeleteThank you for your post, I look for such article along time, today i find it finally. this post give me lots of advise it is very useful for me. nice i like it.
ReplyDelete안전놀이터
메이저놀이터 If more people that write articles really concerned themselves with writing great content like you, more readers would be interested in their writings. Thank you for caring about your content.
ReplyDelete섯다족보
ReplyDeleteIt is said that in life you always get to learn and I am very happy to see your post, I think I will get to learn a lot from your post and I will take inspiration from your post to make my website and post more beautiful Will try
Great survey, I'm sure you're getting a great response.สล็อตวอเลท
ReplyDeleteAwesome and interesting article. Great things you've always shared with us. Thanks. Just continue composing this kind of post.บา คา ร่า วอ เลท
ReplyDeleteYour content is nothing short of brilliant in many ways. I think this is engaging and eye-opening material. Thank you so much for caring about your content and your readers.เว็บ ตรง
ReplyDeleteWe offer product description services in USA. We help convey your product story.
ReplyDeleteSome appear to be executed on the screen of the written text of the content. Who did you do to see if you could deal with this?
ReplyDelete토토사이트링크
토토사이트
바카라사이트
온라인카지노
Are you looking for Best Gutter Installation in Nashville. Gutter Solution provides a proven, tested and permanent solution to the damage caused by clogged gutters. With no holes, gaps, or large openings, Gutter Solution keeps out all types of debris including pine needles, shingle grit, seed pods, and more! Gutter Solution installs directly on your existing gutters to bring you permanent peace of mind and help prevent damages related to clogged gutters.
ReplyDeleteFinding Car Accident Lawyer in Canada? So VSR Law can assist you in recovering damages and ensure that your Motor Vehicle Accident claim is as strong as possible. Car Accident Lawyer in Cambridge
ReplyDeleteLosing the first round of a tournament can significantly impact a player's chances of winning the tournament. Below are three important pieces of information about how losing the first round can impact a player's chances of winning the tournament:
ReplyDeleteRead more: Best Law Schools in Maryland – A Comprehensive Guide
If you're a student in the US, Australia, or the UK and looking for reliable online homework solutions, My Homework Help is here to help. Our platform provides 24/7 support to students in these regions and beyond.
ReplyDeleteAt My Homework Help, we understand that students face a myriad of challenges when it comes to completing their homework assignments. From time constraints to a lack of understanding of subject matter, these challenges can hinder your academic progress. That's why we offer a wide range of homework help services to cater to your specific needs.
Our team of expert tutors is available 24/7 to provide you with the support you need, no matter what subject you need help with. Our tutors are knowledgeable, experienced, and passionate about helping students achieve their academic goals. They will work with you to ensure that you understand the subject matter and are able to complete your assignments with ease.
Such a well-written and informative post! I’m excited to apply the tips you shared in my life.
ReplyDeleteA funded account with FundedFirm is a remarkable opportunity for traders to access substantial capital—up to $100,000—without risking their personal funds, enabling them to develop their skills and generate profits in real market conditions. FundedFirm operates on the advanced MetaTrader 5 platform, offering access to multiple asset classes such as forex, precious metals, indices, energy commodities, and cryptocurrencies, all supported by competitive spreads, low commissions, and leverage up to 1:100, designed to maximize trading efficiency and returns. The program emphasizes disciplined risk management, setting a maximum overall drawdown limit of 6% and a daily loss cap of 5% to protect trader capital while allowing them to execute strategies like scalping, swing trading, news trading, and algorithmic trading with expert advisors (EAs) without restrictions. Traders must successfully complete a two-phase evaluation process, meeting profit targets of 8% and 5% over at least three trading days, demonstrating consistency and skill to qualify for funded accounts. FundedFirm provides fast profit payouts including UPI options for Indian traders, along with continuous educational support, personalized mentorship, and responsive customer service to promote ongoing trader development. This funded account program transcends capital provision; it’s a comprehensive partnership designed to empower traders to transform their talent into sustainable, long-term success within global financial markets.
ReplyDeleteFunded Account
Your blog got me to learn a lot,thanks for shearing,nice article. chesapeake lawyer
ReplyDeleteFundedfirm is dedicated to empowering local traders by providing the institutional capital and professional resources required to dominate global markets. If you are a disciplined strategist looking to scale, securing a funded account in Bangladesh through our streamlined evaluation allows you to manage significant capital without any personal financial risk. We offer industry-leading profit splits, high leverage of 1:100 on the MT5 platform, and a transparent environment built for long-term consistency. By joining the Fundedfirm community, you gain access to elite liquidity and 24/7 dedicated support. Start your journey today and transform your market expertise into a sustainable, high-growth career.
ReplyDeleteFunded account in Bangladesh