Last Thursday evening, I sat at my desk at 23andMe, a genetics company which until very recently offered its customers the chance to divine from their DNA their risks of cancer, heart disease, and many other conditions. I typed out the last lines of a computer program to monitor Twitter and biked home at breakneck speed. When I arrived home, 23andMe had just released the announcement that would set off a Twitter storm: the FDA had ordered it to stop providing its genetic health reports. I set my program running: over the next 48 hours, I recorded more than 4,300 tweets related to the news. What follows is my analysis of two questions: who cared, and what did they think? Any sharp statistician would be suspicious of my objectivity, so I also built a website which will allow you to explore the data yourself: if my conclusions seem unwarranted, please comment or shoot me an email. All analysis is based solely on public data and does not reflect the views of 23andMe.
At peak, roughly 2 hours after the announcement, there were more than 500 tweets an hour relating to 23andMe, or a tweet every 7 seconds. The tweets came from all over the world, as you can tell by tracking the timezone of the tweeter:
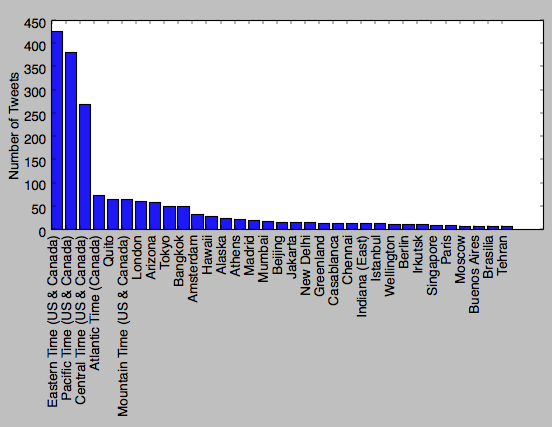
It’s perhaps surprising that there are more tweets from the East Coast than the West Coast, given that 23andMe is a Californian company, but on the other hand the East Coast has more than double the West Coast’s population.
Who were the Tweeters?
A short answer: biologists, geeks, and the politically active. A longer answer: we can use a technique called PCA to make this picture (download it, zoom in, and be patient) of the words Tweeters use to describe themselves in their Twitter profiles. (I include a short explanation of PCA at the end of this post) [1]. Two words appear close together in the picture if they appear frequently together in tweeters’ self-descriptions. From this we can pick out clusters of words which indicate types of Tweeters: near the top, “cancer”, “biotech”, “research”, “genomics”, “biology”, “genetics”, etc: the biologists. Near the bottom, “apps”, “design”, “developer”, “engineer”, “mobile”: the tech nerds. To the right, a combination of health--“lifestyle”, “living”, “healthy”, “live”--and politics: “libertarian” [2], “citizen”, “america”, “environment” [3].
{kind=link}
Another question we can ask is: do people who describe themselves similarly tend to tweet similarly? We answer this by projecting the tweets into two dimensions, projecting the self-descriptions into two dimensions, and seeing whether people who are close in tweet-space are also close in self-description space. The answer turns out to be yes--the correlation in closeness is positive and highly significant. This might be due to the same people tweeting the same things over and over again, so I took them out, and the correlation is still positive. This turns out to be due to a bunch of Tweeters that are described as news sites, who tend to tweet different things than non-news sites. When you take those out, the correlation disappears. I suspect that, in general, people with similar profiles tweet similar things; I also suspect that Twitter, Facebook and Google are way ahead of me on this one.
What did they think?
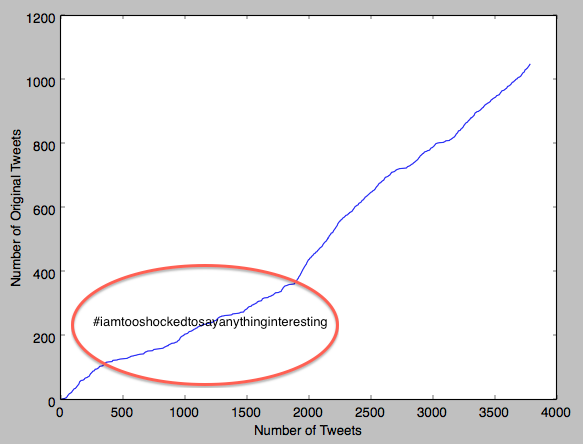
Most people didn’t take a side at all, and just retweeted the news; 74% of the tweets were pretty much exact repetitions of earlier tweets. I was disappointed by this lack of originality, but of course repeating exactly what you’ve been told is often valuable: if you’re a dividing cell, it prevents cancer, and you’re a soldier, it prevents court martials. Here’s a plot of the number of original tweets as a function of the total number of tweets; the changes in slope are interesting. Between tweets 300 and 2000, there are relatively few original tweets, probably because most people are just retweeting the news without really thinking about it.
Most of the people expressing strong opinions supported 23andMe. When we filter on people using profanity, 15/16 tweets blame the FDA. (The exception: “@23andMe This is BS. I only bought these kits to learn about my health, and now I can't. I want my money back!”). When we filter on people expressing negative emotions, 16/19 blame the FDA (42 people express negative emotions, but 23 of them just say that they’re “sad”, leaving blame ambiguous). I wondered if looking only at negative words biased the sample towards people who feel negatively towards the FDA, so I looked instead at words indicating positive emotion, and found that 15/20 people who took a definite side favored 23andMe. I also looked at people expressing opinions on the lawsuit against 23andMe; 32 people simply retweeted news stories about the lawsuit, but of the 7 who took a side, all said the lawsuit was frivolous. Finally, when I looked at people with backgrounds in science, medicine, or biology, 17/20 who took a definite position supported 23andMe. There are also 52 tweets from libertarians who mock the #nannystate, a tweeter who refers to 23andMe CEO Anne Wojcicki as a “gummy bear”, and a Canadian who is so upset about the whole thing that he says “#IDontWantToLiveOnThisPlanetAnymore”. Of course, Twitter users probably represent a biased population: they may be exactly the sort of young, free-spirited, tech-savvy individuals who would like a company like 23andMe.
Whatever happens, we are lucky to live in such exciting times. In the words of Tweeter @LibrariNerd from Nilbog:
I’ve been saving all the emails I’m getting from 23andMe about it. Feels potentially historical.
Notes:
1. PCA is an elegant technique that helps you visualize “high-dimensional data”, which has become a buzzword in our information-rich world. High-dimensional data just means that each datapoint takes a lot of numbers to represent: a Twitter post can be represented by a long row of ones and zeros, where each one or zero refers to the presence or absence of a certain word; a genotype (what we have at 23andMe) can be represented by a row of zeros, ones, and twos, where each number describes a particular location in the genome. High-dimensional data is difficult to visualize--we don’t do well in more than 3 dimensions--but PCA allows you to project the data down into 2 dimensions in a way that retains an essential property: points that are close together in the high dimensional space will be close together in the 2 dimensional space.
2. “Libertarian” also appears right next to “single”, on which I have no comment. 3. Those familiar with PCA will note that this is a projection of the words, not the self-descriptions: the transpose of the document-term matrix. You can also project the original matrix, but it’s harder to fit the self-descriptions on one page; from what I could make out, you get a continuum of “biologist” to “general nerd”.
4. I used Python’s difflib for string comparison with a threshold of .8.
5. This dataset is somewhat incomplete for two reasons. a) I upgraded my program while it was running (so it could collect Tweeter self-descriptions and time zones as well as the raw tweets) and b) it crashed at 2 AM the first night, so there’s a period of a few hours when I’m missing data.
6. A note on the website: the website is known to have certain minor bugs which I will fix when I get the computer on which the code resides back from my boyfriend.
Great article. Cheer!!
ReplyDeleteดูหนังออนไลน์ หนังไทย
One explanation that drug rehab is a decent arrangement is on the grounds that you can rely on being abstinent, in any event while you are there. In a great deal of cases, individuals who attempt to get perfect can not make it to the 24 hour imprint and they have just backslid, essentially in light of the fact that they are stuck in a domain that is encircled by drug and liquor use. In any event in rehab, you will have the option to get spotless and calm and dried out for half a month with the goal that you can at any rate get your heading. It is a controlled domain so in any event you will get the chance to encounter some lucidity for some timeThe second explanation that it bode well to go to rehab is on the grounds that you will be getting a huge amount of help while you are there, and after you leave. It is the individuals in recuperation that help us to remain calm and you need those individuals throughout your life. You can meet a great deal of ground-breaking associations in a rehab office.
ReplyDeleteoutpatient drug rehab florida
florida rehab center
I'm sure that the classification area – or labels on YesPornPlease – is where the majority of you will be going to truly get your hands on the muck you want. Note that close by broad labels, you can likewise take a gander at labels for specialists, characters and assortments explicitly – YesPornPlease is very careful in such manner. In any case, you have famous ones here, for example, butt-centric and sensual caress clo-se by more specialty interests, including stockings and catgirls. I've since quite a while ago cherished the way that these master hentai center points consistently have exhaustive classification and a wide exhibit of fixations to request the bizarre and magnificent universe of hentai on the web. Everything looks OK, from the people behind this top-level anime XXX library – Mr. Pornography Geek truly prefers what he sees!
ReplyDeleteyespornplease
yespornplease.com
Indeed yespornplease presents to you the best free pornography recordings you can discover on the net.
ReplyDeleteThat is the reason yespornplease is your best choice with regards to picking XXX porno. You can't, and you would prefer not to pass up all that we've gathered for your delight. You would not quit watching the best recordings realizing which is the page where you will discover them. You have effectively discovered it and you can not miss the second to load up with joy taking a gander at the most sweltering and tasty Internet. All deliberately chose with the goal that every video puts you at a thousand and you generally need to return for additional. Of that we are certain, you will like such a lot of that you will return.
We as a whole know the xxx recordings of yespornplease however on our site you can discover the cream de la cream, separating the inferior quality substance. You will presently don't need to sit around investigating recordings and picking the ones with the best quality and substance, we will do it for you.
We're staying put and you'll wind up thinking of us as the best form of yespornplease we buckle down for. We need to please tastes and stay perpetually, we realize that this is accomplished exclusively by offering quality and that is our main thing. That is the reason we welcome you to visit us. We realize that once you see the nature of our material, you will get diligent to our page.
A page where your porno minutes will be the most agreeable and best. You will not need to move from here. You can appreciate and fill yourself with joy without leaving our site briefly.
Need to see free versatile pornography in excellent and HD?
On our site you will appreciate watching the best yespornplease.com motion pictures. We sincerely feel that our guests merit what we think they merit. Great, enduring, top notch motion pictures. They merit not to lose subtleties of the scenes introduced by every film they need to see. That is conceivable, in light of the fact that we have an assortment of the best films in HD quality. So you can appreciate the best of the most sultry and distorted snapshots of every video you need to see.
Yespornplease is the ideal spot to observe free pornography video here you will track down the best pornography recordings of the whole organization.
In the event that you can appreciate quality and assortment here. Yespornplease have great material, complimentary and we are continually reestablishing. So you can be certain that with us your fun and joy won't ever end. Try not to make due with something tolerably great, in case you will track down the best on this page.
We offer free pornography video XXX so you can make the most of your sexuality
Why yespornplease and not another page?
Since there could be no other spot like Yes pornography where to observe free pornography recordings of the greatest HD quality and totally horny, similar to our site. Make the most of your sexuality to the greatest, make some great memories and get those climaxes you need such a huge amount with the material we have for you.
yespornplease is the spot, come in and you will consider that to be with the expectation of complimentary pornography films we have no opposition. We are the awesome. There could be no other equivalent and there will not be. We work pondering your fulfillment consistently. We search for simply the best material.
This comment has been removed by the author.
ReplyDeleteIt looks like you have spent a lot of time in this article. It is a nice informative content. I am impressed. Nice post. Thanks for sharing. Now its time to avail spanx discount code for more information.
ReplyDelete