Correlation matrices are like the lover you just can’t let go: complex and deceitful, but too irresistibly fascinating to abandon. A year ago, when they made me crash Stanford’s supercomputer for the third time, I almost swore them off forever. But I’ve been flirting with them frequently in the past few weeks, and I’d like to write about our reconciliation. First I'll describe what they are; then I'll give five cool examples of why they're useful.
What's a correlation matrix? It’s a square table that describes how variables go up or down together. Here’s an example:
Snowy Outside
|
Wear a Sweater
|
Snuggle by Fire
| |
Snowy Outside
|
-
|
.8
|
.7
|
Wear a Sweater
|
.8
|
-
|
.2
|
Snuggle by Fire
|
.7
|
.2
|
-
|
Each entry in the table is the correlation between two variables, a number between -1 and 1 where positive correlations mean that when one variable goes up, the other one tends to as well; negative correlations mean that when one variable goes up, the other tends to go down. In the example above, snow and sweaters are strongly correlated, and snow and snuggling are too, but sweaters and snuggling are less strongly correlated. (Usually I get too warm when snuggled in a sweater, and am less inclined to snuggle the sweatered as well.)
This is useful because it lets us rapidly see how groups of variables are related and pick out variables that are connected. Here are five brief examples which I may write about in more detail later -- click on the links, the pictures are cool.
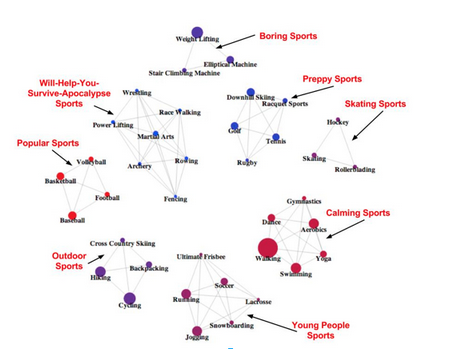
-We can look at the 23andMe customers who play 39 different sports, and compute the correlations between sports (full post, in honor of the Olympics, here), and divide sports into groups that tended to be correlated. This lets you see groups of sports that tend to be played by the same people: preppy sports, boring sports, lethal sports, etc.
- We can compute correlations between flavors or ingredients in cocktails, which lets you see which ingredients and flavors tend to be used together, and potentially invent your own cocktails. Here are flavors:

- We can look at the commenters on different New York Times forums, which shows you which New York Times forums tend to share commenters -- the female-dominated forums about fashion, health, and parenting, for example.
- We can look at how levels of gene expression covary in the human body, which can reveal groups of genes that work together: here’s a cluster with immune functions within the blood. (The full tool I built is here.)
- We can compute the correlation matrix for 500 last statements of Death Row inmates (thank you, Texas) where our variables are things like mentioning family or expressing anger:
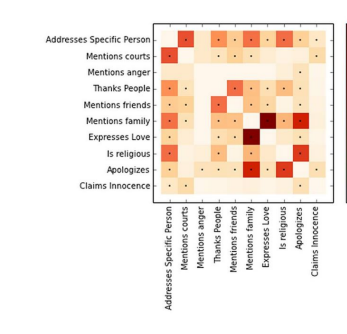
The darker a square is, the more strongly two variables are correlated: the strongest correlation is between mentioning family and expressing love, which should make you maybe think twice about the people we’re executing.
So one technique can lend insights into everything from alcohol to execution. Amazing, right? What’s the catch? There are at least three problems with correlation matrices [1]:
1. They can lie to you. In the snow example given above, it’s possible that wearing a sweater actually causes you to be less likely to snuggle, all else being equal, but the correlation still appears positive because wearing a sweater is a sign that it’s cold, which is the true cause of snuggling.
2. They can be too big. If I have 10,000 variables, I’m going to need a table that’s 10,000 x 10,000, which is how I crashed Stanford’s supercomputer (I was trying to compute correlations for 10,000 genes in 35 different tissues simultaneously.) This isn’t just a problem because you crash your computer: it’s also because when you compute a table that’s 10,000 by 10,000, you’re computing the values of 50,000,000 variables, and to do that accurately, you need a lot of samples, which you often don’t have. That means that you can’t really trust the values you compute.
3. They can produce knots that are hard to untie. My sports example makes it look like there are eight beautiful groups of sports that separate perfectly:
But of course that isn’t really the case: all the sports are somewhat correlated, it’s not like no one who skis plays baseball. But if you actually drew all those correlations, you’d end up with a giant hairball. For example, when I finally got the Stanford supercomputer to compute covariance matrices for my genes, here’s what I found the BRCA1 (breast cancer) gene tended to covary with in breast tissue:
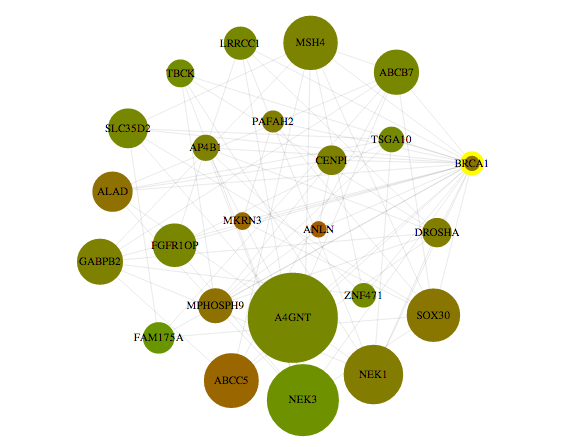
There are 24 genes here with hundreds of links, and it’s very unclear how to make sense of them. To deal with this problem we often try to reduce the number of links, either by ignoring links unless the correlation is very strong or by using more sophisticated techniques.
Notes: [1] All of which have analogues in love.
This comment has been removed by a blog administrator.
ReplyDelete