How do we map the density of a set of events? For example, we might want to map locations of tweets supporting Bernie Sanders as opposed to Hillary Clinton or locations of housing evictions or locations of police shootings. I confronted this problem recently while writing a post for Quartz (which they split into two) about where people tweet more about wine and where they tweet more about beer. Here’s a finished map (you can see more in the Quartz posts); color shows the fraction of #beer or #wine tweets which are about #wine, with red denoting pro-#wine areas.

I built a tool which lets you make maps like this, and because I think this problem is often useful to solve and often solved badly, I provide some thoughts on how to make maps below. If you’re not interested in details, you should probably just look at the maps in the Quartz posts, but if you keep reading you’ll at least get to see me make a lot of bad maps.
One simple thing to do is just to make a state-by-state map where each state’s color corresponds to the density of events. This has a few problems. It requires us to map all the latitude, longitude pairs to their states, and if we want to look a country besides America, we need to adapt our method; more fundamentally, it’s not very high-resolution, and there are often interesting patterns at the sub-state level.
To get better resolution, people often just plot the exact latitude, longitude location of the tweets, so you get visualizations that look like this:
Which is pretty but not very useful (like your momma!) because it basically just shows us where the cities are. (I have lost track of the number of data analyses I have read that can be summarized as, “when you have more people, more things happen”).
What I think you usually want to do is plot the density of events relative to some background. For example, I don’t care about the absolute density of wine tweets, which will be heavily correlated with population density; I care about the fraction of beer/wine tweets which are wine tweets.
So one thing we can do is estimate the density of wine tweets, estimate the density of beer tweets and then plot the difference: densitywine - densitybeer. (We can estimate density using a method called, appropriately, kernel density estimation). Here’s what happens when we do that; red denotes areas with more wine, blue with more beer.
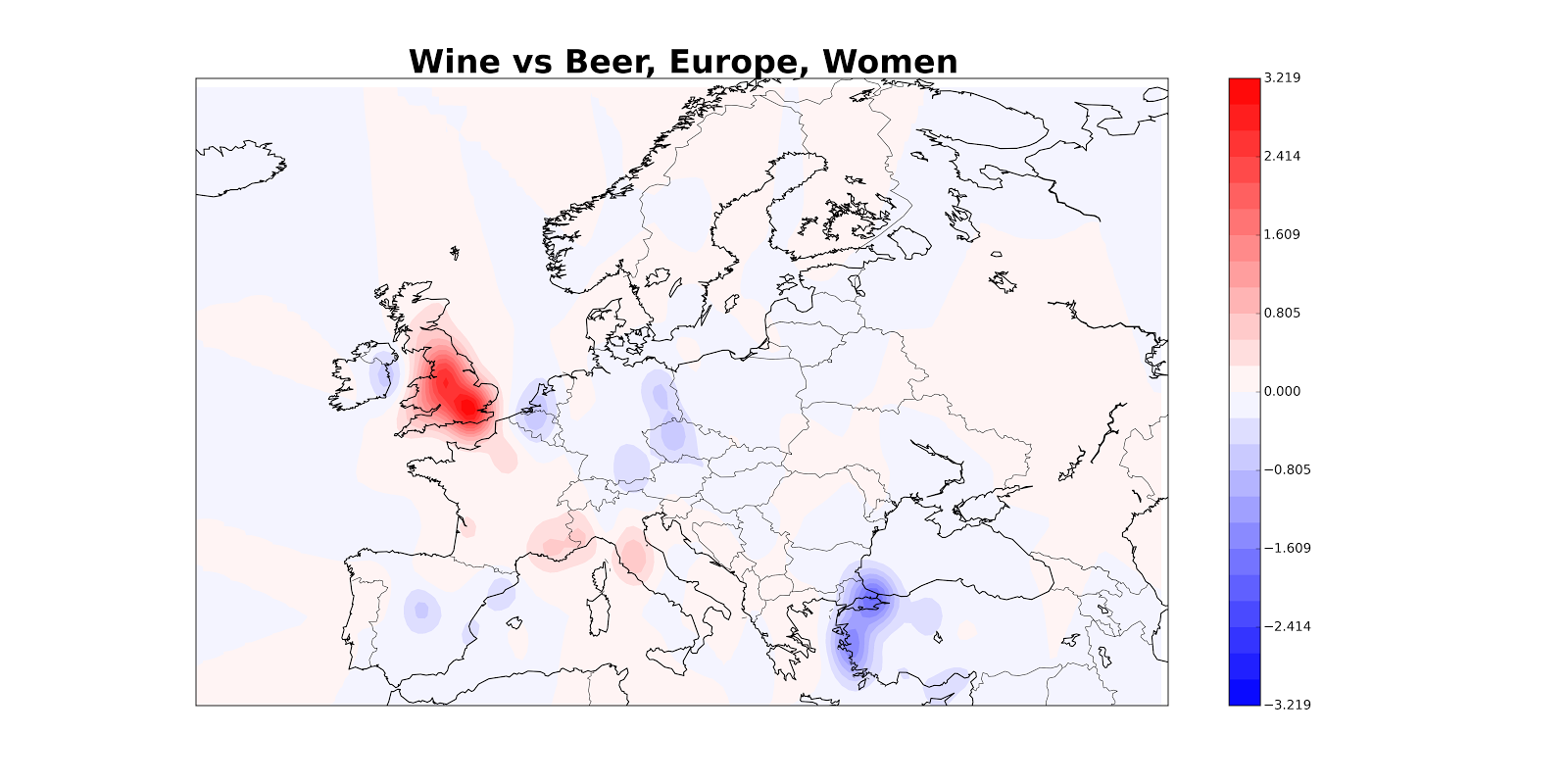
The problem is that the reddest areas aren’t necessarily the areas where 90% of people are tweeting about wine; they might also just be the areas with a ton of tweeters (which will also have larger differences between densitywine and densitybeer). So maybe we really want something like densitywine / (densitybeer + densitywine), which we can interpret as the fraction of tweets which are about wine. Here’s what that looks like.
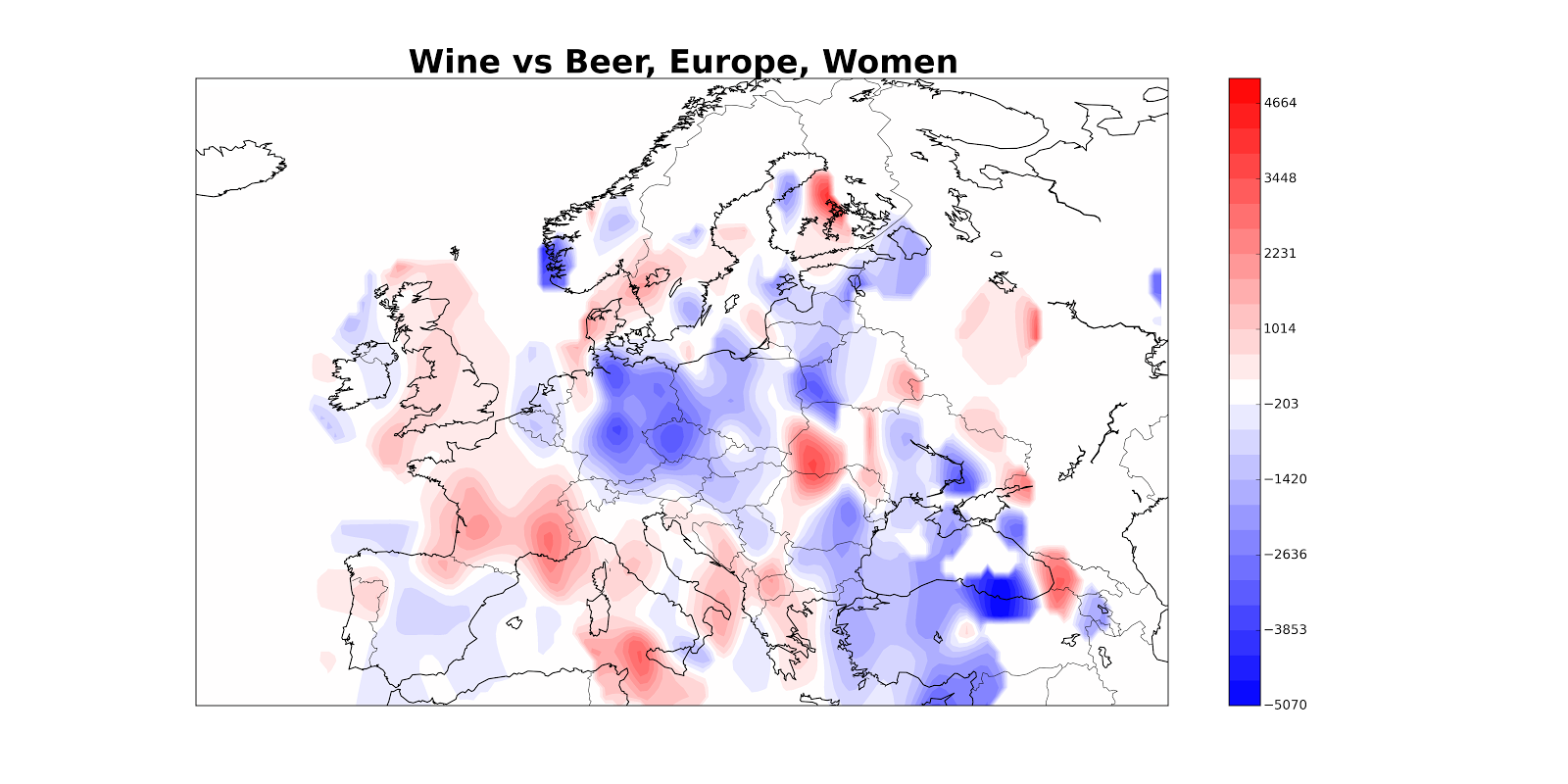
The problem, basically, is that the ratio of two things is unstable when the denominator gets small, which often happens. I tried various ways of getting around this but they were finicky.
So here’s an alternate solution: for every point which you want to color, look at the closest 10 beer/wine tweets and see how many of them are about beer. It seems like this will take a really long time if we have, say, 10,000 points and 50,000 tweets. Luckily, computer scientists have devised an efficient way of doing this which takes about two lines of code and a second to run (#MyFieldIsCoolerThanYourField) [1].
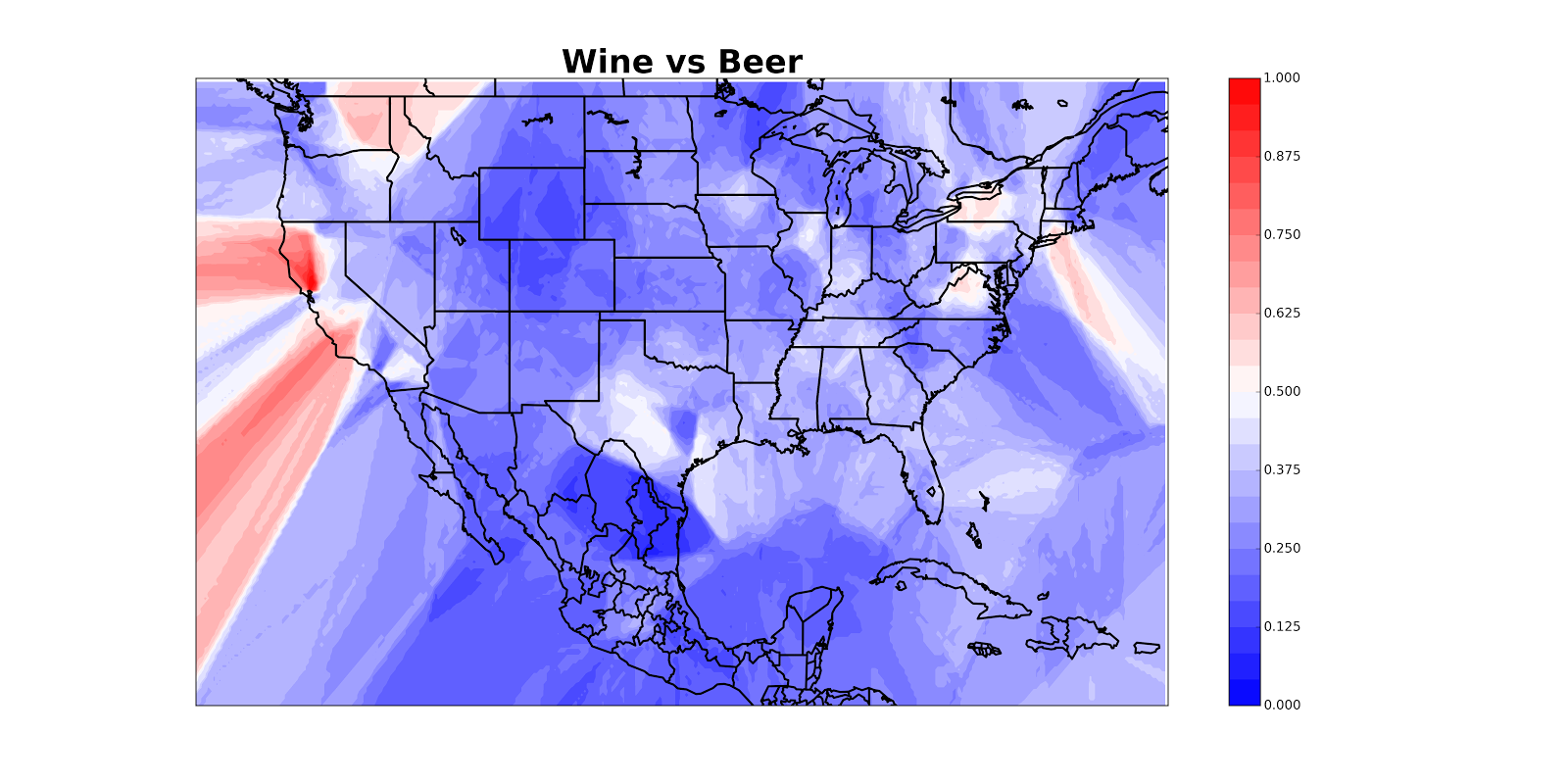
This doesn’t look so good because California appears to be hemorrhaging, but once we mask off the oceans we get a nice map:
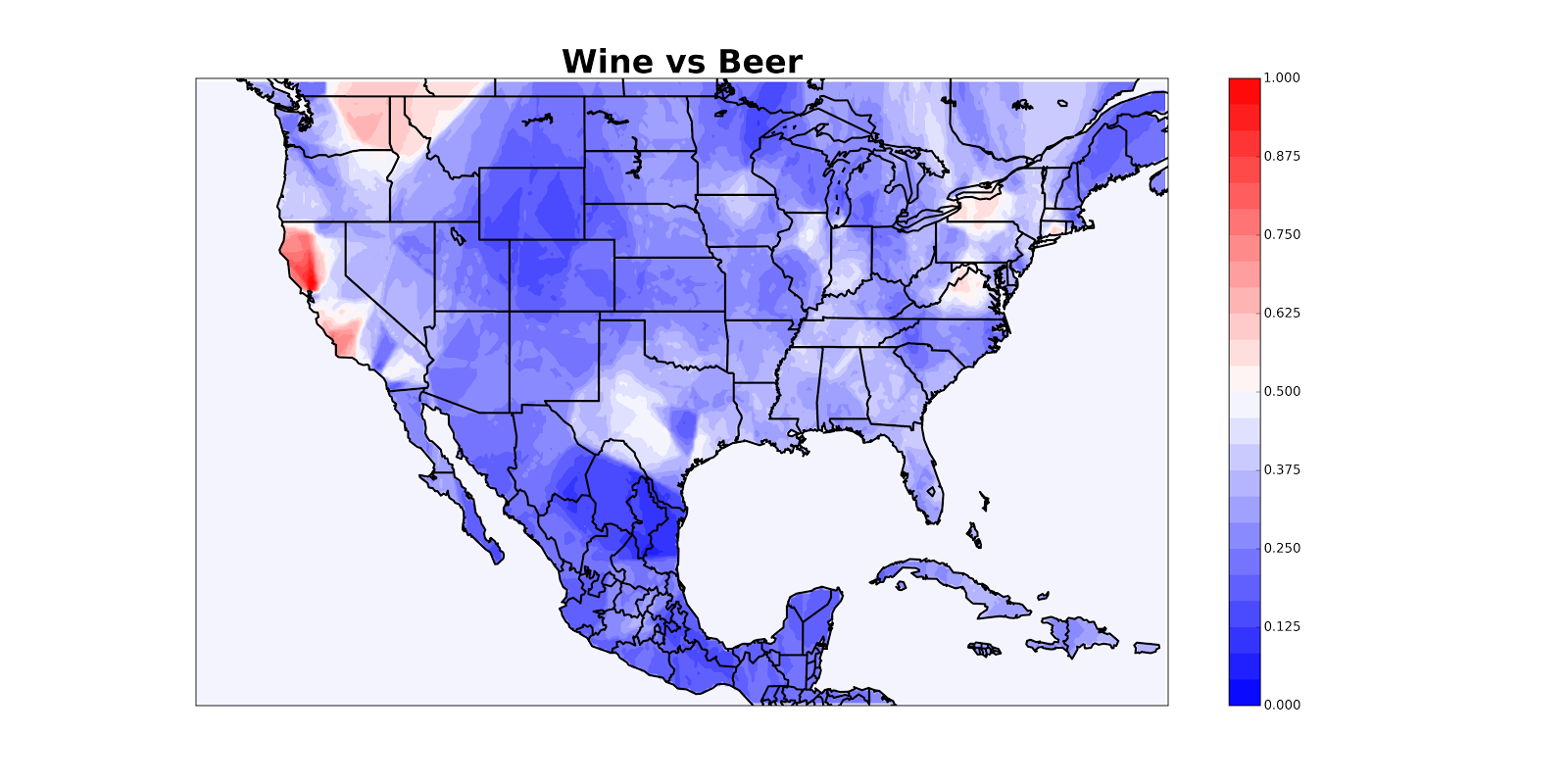
I’ve posted the code to make maps like these on GitHub so you can make maps of your own (and let me know if you find anything cool)! Keep in mind that the map will be less reliable in areas with little data. You can use it on any data (not just from Twitter) that has latitude and longitude. It requires knowledge of Python, so shoot me an email if you get stuck. If I get enough complaints from people who want to make maps but can’t use Python, I’ll just build a web tool.
Also, I am not a mapmaking expert, so feel free to tell me how I could’ve used CartoDB or whatever to do all this! (My problem with CartoDB is that the free version won’t keep data private and limits the size of your datasets to 50 MB. I’m not really a 50 MB kind of girl.)
Notes:
[1] We just train a k-nearest neighbors classifier and plot its classification surface. There’s also the question of how you choose the number of nearest neighbors to look at. If you choose too small a number, the map gets very splotchy:
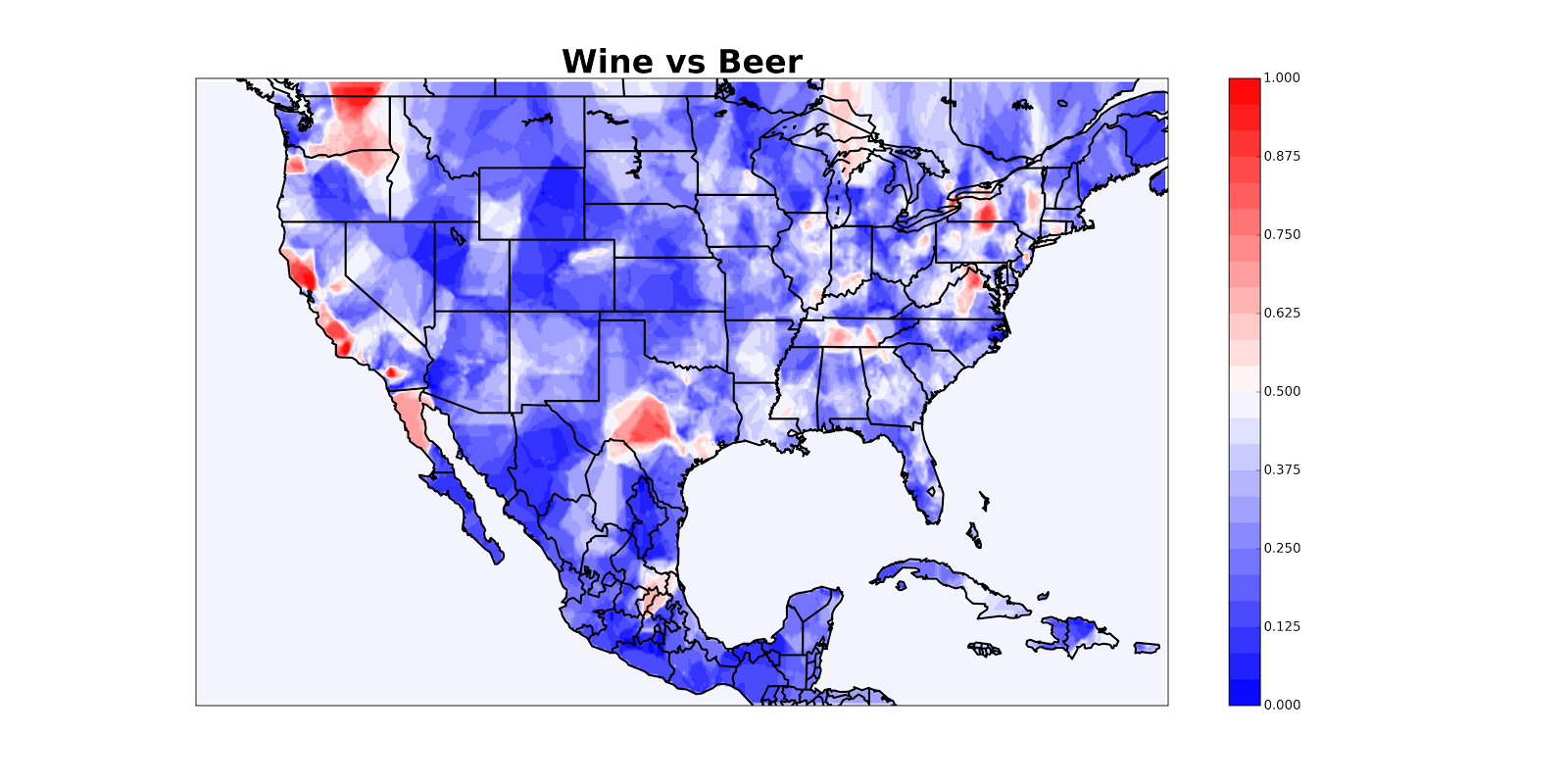
And if you choose too large a number, you lose real details. I’m not exactly sure how best to choose, so hit me up if you have thoughts. Do not tell me to use cross-validation. Seriously, we’re mapping drunk tweets here.
A final note: this tool obviously relies on you having latitude / longitude data. Many datasets are not in this form (eg, they might include addresses instead) and I have not found a great way to rapidly convert between addresses and latitudes / longitudes, because many APIs are rate limited. Let me know if you have a good solution to this problem.
Very cool, and interesting. Public health / epi Mike from NC here ... reminds me of ggplot2's viz asthetic, which I love. I'll be taking a look at this for some other R projects, and given the commonalities in python and R, I expect this will be a great learning tool. Thanks for sharing.
ReplyDeleteThanks, I'm glad it was useful to someone :) I don't like R, but I love ggplot2.
DeleteI have an unusual amount of data in the form of "Long/Lat, {0,1}", and I've always wanted to make maps like this with them but never found the time, so I'm excited to see your code! How well do you think it scales?
ReplyDeleteCool! How many points do you have?
Delete~100 million, but dramatically downsampling is just a fact of life. How many tweets were in there?
DeleteHey emma ,
ReplyDeleteYour doing a great job, delivering such valuable content is not easy. Keep doing !
Academic Editing and Proofreading Services
Academic Proofreading Services
Thank you for taking your time and explaining about the importance of professional editors.
ReplyDeleteAcademic Editing and Proofreading Services
Academic Editing Services
Academic Proofreading Services
Article Editing Services
Article Writing Services
Journal Article Editing Services
Book Editing Services
Book Writing Services
The information you shared is nice. We also share a post on Name change services Name change is available professional services in name change industry. For any assistance talk to us or call us:- 9871075159 and find free consulting.
ReplyDeleteNAME CHANGE IN GAZETTE
NAME CHANGE AFTER MARRIAGE
NAME CHANGE DOCUMENT
NAME CHANGE AFTER DIVOCE
NAME CHANGE AFTER INTER RELIGION MARRIAGE
Thanku for sharing an informative post. I also share a post on fire station .A-onefire is the best fire saftey service provider in delhi . For any help please call us:-9811057544 then we provide a better service.
ReplyDeleteFor more information visit my website given below :
website : https://www.a-onefire.in
Firestation
Fireservices
No 1 Fire AMC company india
Fire fighting maintenance
We are a free specialist co-op for all the equipment and programming related issues.We are an outsider organization giving specialized help in programming, PCs, PCs, printers and so forth.
ReplyDelete||HP Printer Support Toll Free Phone Number
||hp printer tech support phone number
||hp printer customer service number
||Samsung Printer Support Toll Free Phone Number
||samsung printer tech support phone number
||samsung printer customer service number
||Brother Printer Support Toll Free Phone Number
||brother printer tech support phone number
||brother printer customer service number
||Lexmark Printer Support Toll Free Phone Number
||lexmark printer tech support phone number
||lexmark printer customer service number
||Dell Printer Support Toll Free Phone Number
||dell printer tech support phone number
||dell printer customer service number
||Epson Printer Support Toll Free Phone Number
||epson printer tech support phone number
||epson printer customer service number
||canon Printer Support Toll Free Phone Number
||canon printer tech support phone number
||Canon printer customer service number
Thank you for all of your work on this web page.
ReplyDeleteบาคาร่าUFABET
that’s awesome.
ReplyDeleteวิธีเล่นบาคาร่า
If you found any common issues in your Quickbooks like login issues, connectivity issues, Printing errors, PDF related issues, and Performance issues, you can simply download QB Tool Hub which is the combination of all essential tools to fix common issues.
ReplyDeleteQuickbooks tool hub download
We do not charge a single penny if our technicians fail to repair your device. No one other than Geek squad can provide instant & same services at the same reasonable prices.
ReplyDeleteFor more information visit site :- Geek Squad tech support
google 1744
ReplyDeletegoogle 1745
google 1746
google 1747
google 1748
I want to testify on how I got cured from Herpes. I have been living with this disease for the past 11 months, i have done all i can to cure this disease but all my efforts proved abortive until i met an old friend of mine who told me about a herbal doctor called Dr Oniha, she told me that Dr Oniha have cure for all kinds of diseases, though i never believed in it because my believe was that there is no cure for Herpes disease. But I decided to give it a try when I contacted Dr Oniha, he told me he has a cure for herpes that he cured with herbal medicine. I order for the herbal medicine, which Dr Oniha sent to me through a courier service which i make use of and now behold the herpes is gone and i now have my life back,if you are out there living with this disease i will like you to also contact Dr Oniha and get this disease cured out of your body. I am a living testimony of Dr Oniha herbal cure. Thanks once again Dr Oniha for you are God sent. contact Dr oniha through his contact information.
ReplyDeleteEmail:driyaseherblahoe@gmail.com
Whatsapp number: +2347057052206
ReplyDeleteشركات نقل عفش ونظافة ومكافحة حشرات
شركات نقل عفش ونظافة ومكافحة حشرات
شركات تنظيف بالطائف
شركة تنظيف بالطائف
شركة تنظيف خزانات بجدة
شركات تنظيف بالطائف
نقل عفش بالرياض
شركات نقل العفش بالرياض
After exploring a handful of the blog posts on your blog, I seriously like your way of writing a blog 카지노사이트
ReplyDeleteI am glad to discover this page. I have to thank you for the time I spent on this especially great reading !! I really liked each part and also bookmarked you for new information on your site. Feel free to visit my website; 토토사이트
ReplyDeleteThis really is an incredibly amazing powerful resource that you’re offering and you just provide it away cost-free!! I comparable to discovering websites that view the particular price of providing you beautiful learning resource for zero cost. We truly dearly loved examining this web site. Be thankful! Feel free to visit my website; 배트맨토토
ReplyDelete
ReplyDelete가평출장안마
금산출장안마
가평출장안마
아산출장안마
당진출장안마
부여출장안마
양평출장안마
양평출장안마
Looking to volunteer for an education-focused NGO in Delhi? Join Teach India, a program by Times of India, and make a positive impact on the community.
ReplyDeletehttps://www.infragistics.com/community/members/139fb676ee35f06c66b3cb1c3bc03344e4cd62d8?_ga=2.73380179.1938063357.1680165158-1746912433.1680165158/
Way2oz provides detailed information on Offshore Parent Visa Subclass 103, guiding individuals through the application process for parents to join their Australian citizen, permanent resident, or eligible New Zealand citizen children in Australia. https://www.way2oz.com/offshore-parent-visa-subclass-103
ReplyDeleteDivine Interiors offers exquisite PVC plantation shutters in Melbourne that combine elegance and durability. Transform your space with their high-quality and customizable window coverings. https://divineinteriors.com.au/plantation-shutters-melbourne
ReplyDeleteNextGen Steel Frames provides robust Steel Roof Truss in Melbourne, Australia. With their advanced engineering and quality materials, ensure stability and durability for your roofing projects. Choose NextGen for reliable steel truss solutions.
ReplyDeleteVelementWW: NYC Sign Company. Transforming brands with captivating signs and graphics. Unmatched quality and creativity. Elevate your brand today.
ReplyDeleteBoost your website's visibility with our comprehensive Directory Submission List from SEO Khazana. Increase traffic and rankings. Improve your SEO today!
ReplyDeleteMe voy de esta publicación con un nuevo optimismo, ansioso por enfrentar los obstáculos de la vida con una mentalidad positiva y una esperanza inquebrantable. La CPS test es un cambio de juego para aquellos que buscan refinar su mentalidad analítica.
ReplyDeleteExplore the Flysky radio ecosystem extensively and uncover advanced tips and techniques to enhance the performance of your Flysky Noble NB4. Maximizing Flysky radio experience effectively.
ReplyDeleteDiscover Bhopal's Best School, Raj Vedanta School. Experience academic excellence, holistic development, and a nurturing environment for your child's growth.
ReplyDeleteExplore impactful Corporate Leadership Training at The Institute of Purpose. Unleash your potential and refine your leadership skills to achieve success.
ReplyDeleteExplore the significance of Due Diligence for Startups in establishing a strong foundation for startup success. Discover how EaseUp can effectively guide you through this process for optimal results.
ReplyDeleteJade Homes proudly stands as the Best Home Construction company in Delhi-NCR. With a track record of excellence, innovation, and client satisfaction, we turn your dreams into reality. Choose Jade Homes for the finest in construction and craftsmanship.
ReplyDeleteMigrate from Wave to Zoho Books? Let MMC Convert handle your migration hassle-free. We ensure a smooth transition of your financial data so you can focus on your business. Make the move with confidence; choose MMC Convert.
ReplyDeleteEfficiently extract Mobile Receipt data extraction with MMC Receipt. Streamline your record-keeping and simplify expense management.
ReplyDeleteRK Cot Weaving is a leading name in Cotton Drill Fabric Manufacturers. Experience top-notch quality and durability in every weave.
ReplyDeleteAxcel Gases provides high-quality Helium Gas Cylinder, ideal for various applications such as helium-filled balloons, medical equipment, and scientific research. Trust us for your helium needs.
ReplyDeleteDDK Healthcare excels in Urology, offering cutting-edge solutions for urinary tract disorders. Trust our expertise for your urological needs.
ReplyDeleteThe Amritsar Group of Colleges offers the Best Engineering Course in Punjab, combining quality education, industry relevance, and state-of-the-art infrastructure, making it a preferred choice for engineering aspirants.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThe Skilled Employer Sponsored Regional Visa Subclass 494 is for skilled workers sponsored by employers in regional Australia. Way2oz offers expert assistance for a smoother visa application process, making regional employment more accessible.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteBullseye Home Builders excels in Townhouse Development in Melbourne. We bring innovation and expertise to create outstanding, multi-unit living spaces.
ReplyDeleteEnjoy Indian IPTV in Australia with Maxx TV! Immerse yourself in a world of diverse entertainment, including movies, shows, and channels from India. Maxx TV delivers a seamless and enriching viewing experience, bringing the best of Indian content to your screen.
ReplyDeleteWay2oz, your trusted Migration Agent in Williams Landing, offers expert guidance for a smooth immigration process. Count on their experience to navigate visas and residency, ensuring a successful transition to your new life in Australia.
ReplyDeleteSecure specialized Home Loan For Doctors in Melbourne, Australia with Jump Financing. Enjoy exclusive rates and tailored solutions to make your dream home a reality. Your path to homeownership is customized for medical professionals.
ReplyDeleteElevate your space with VelementWW! We craft Custom Signs in NYC that speak your brand's language.
ReplyDeleteIf you're looking to purchase binoculars online India, there are numerous online platforms that offer a wide variety of options to suit your needs. Whether you're an avid birdwatcher, a sports enthusiast, or simply someone who enjoys observing nature, you can find the perfect pair of binoculars with just a few clicks.
ReplyDeleteOnline shopping provides the convenience of comparing different brands, specifications, and prices, ensuring that you make an informed decision. Many websites also feature customer reviews, which can help you gauge the performance and quality of the binoculars before making a purchase.
Your post was very thorough and thoughtful. I now have a clearer understanding of the topic!
ReplyDeleteFascinating post! I really appreciate how Emma walks us through the challenges and clever solutions in mapping event densities—especially the intuitive explanation of kernel density estimation and the ingenious use of k-nearest neighbors for visualizing relative tweet frequencies. Your transparency about the limitations, alternative approaches, and the shared code on GitHub makes this not just an insightful read but also a highly practical resource. It’s a perfect guide for anyone working with geospatial data. If someone’s looking for additional support or tips—say, for an Essay Writing Services project that involves data visualization—this post is an excellent foundation to build on. Keep up the great work!
ReplyDelete