Here’s an interaction you might’ve participated in:
Member of minority group: I just had [negative interaction] with John. I don’t think he would’ve done that if I hadn’t been a minority.
Listener: That sucks. But...how do you know it was because you were a minority? Maybe he was just having a bad day or he was really busy or …
The negative interaction might be, say, that John talked down to them or didn’t include them on a project. The listener’s reaction is totally reasonable and well-intentioned (at least, I hope it is, because I’ve had it myself). Sometimes it isn’t even said out loud; the listener just thinks it. Here I argue that this reaction is not the most useful one. I explain why, both in English and in math, and then I suggest four more useful reactions.
The problem with this reaction is not that it’s false. It’s that it’s obvious. If a minority tells you about something bad that happened to them, you can almost always attribute it to factors other than their minority status. (Throughout this essay, I’ll refer to negative behavior that’s due to someone’s minority status as “discrimination”.) Worse, this uncertainty will persist even if the discrimination occurs repeatedly and is quite significant. The core reason for this is that human behavior is complicated, there are lots of things that could explain a given interaction, and in our lives we observe only a small number of interactions. Because it is so hard to rule out other factors, individual discrimination suits have notoriously low success rates.
Let’s be clear: I’m not saying you can never prove discrimination from someone’s individual experience. Obviously, there some experiences which are so blatant that discrimination is the only explanation: if someone drops a racial slur or grabs their female coworker by the whatever, we know they’re a president bigot. But, in today’s workplaces, problematic discrimination is rarely so overt -- hence the term “second generation” discrimination. Here’s a picture:

Here’s a simple mathematical model that formalizes this idea. If you don’t like math, feel free to skip to the “What should we do instead” section. Let’s say the result of an interaction, Y, depends on a number of observable factors, X, one of which is whether someone’s a minority. Specifically, let:
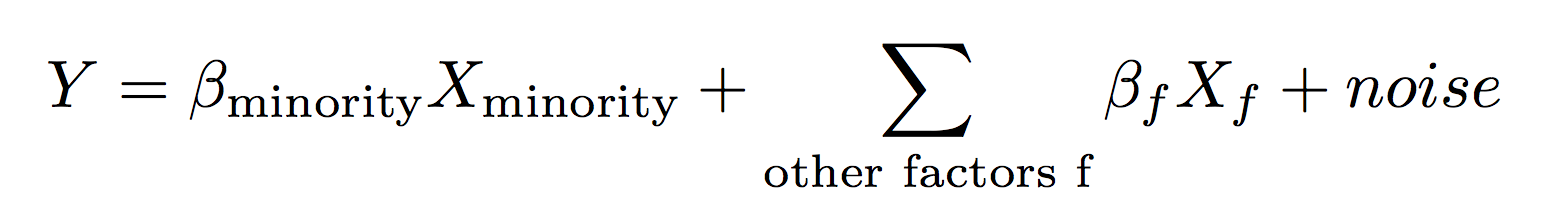
where beta is a set of coefficients describing how much each factor matters, and noise is due to random things we don’t observe. So, for example, Y might be your grade on a computer science assignment, X might include factors like “does your code produce the correct output” and “are you a minority” and noise might be due to stuff like how quickly the TA is grading [1].
If we want to know whether there’s discrimination, we need to figure out the value of betaminority: this will tell us whether minorities get worse outcomes just for being minorities. We can infer this value using linear regression, and importantly, we can also infer the uncertainty on the value.
Here’s the problem. When you do linear regression on a small number of datapoints (which is all a person has, given that they don’t observe that many interactions) you’re going to have huge uncertainty in the inferred values. To illustrate this, I ran a simulation using the model above with two groups, call them A and B, each half the population. I set the parameters so there was a strong discrimination effect against B. Specifically, even though A and B are equal along other dimensions, the average person in A will be ranked higher than about two thirds of people in B, due solely to discrimination; if you look at people in the top 5%, less than a third will be B. So this is enough discrimination to produce substantial underrepresentation. But when we try to infer the value of the discrimination coefficient, we can’t be sure there’s discrimination. In the plot below, the horizontal axis is how many interactions we observe; the blue area shows the 95% confidence interval for the discrimination coefficient (with negative values showing discrimination against B); the black line shows a world with no discrimination.
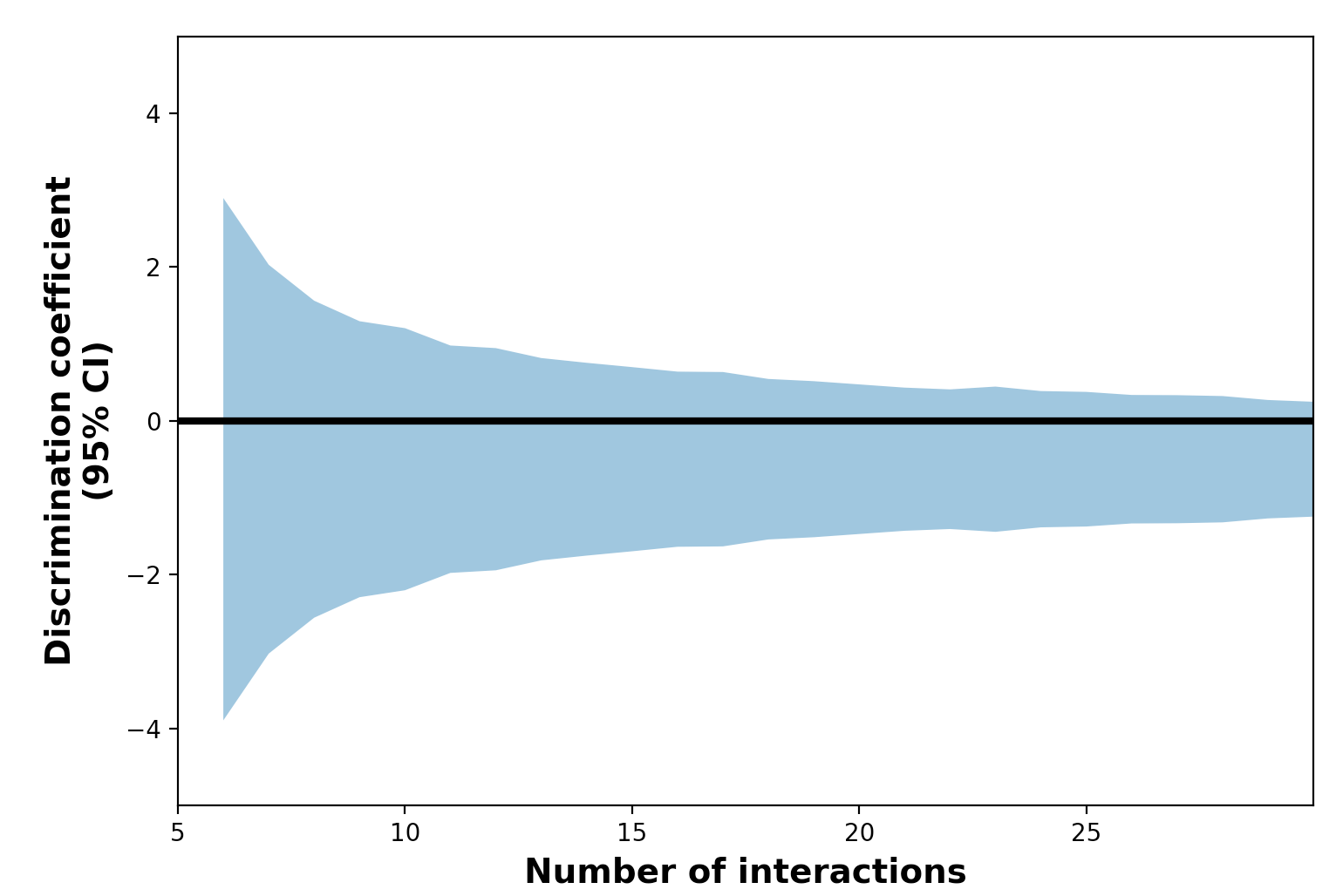
The important point being that the blue shaded area overlaps 0 -- meaning no discrimination is possible -- even if you have literally dozens of interactions, which is way more than you often have. (For fewer than about 5 interactions, the errorbars just blow up and you can’t even graph it.) You can alter simulation parameters or simulate things slightly differently, but I don’t think you’ll change the basic point: you can’t infer effect sizes on sample sizes this small with any confidence.
This model also illustrates some features which make concluding discrimination harder. For example, our errorbars will be larger if other features in X are correlated with being a minority. (“No no, I didn’t promote him because he’s a man. I promoted him because we work well together because we always go out to dinner together / play basketball together / he sounds so much more confident. Well, yes, my wife says I can’t go out to dinner with women…”) Also, your errorbars will be larger if you’re observing repeated interactions from the same person. (If you’re trying to compare your treatment to that of a single coworker, it’s even harder to be sure if it’s because you’re a minority or because of one of the innumerable other ways in which you’ll inevitably differ.) Last, you’re going to be in even more trouble if your minority is a very small fraction of the population whose interactions you observe (say, computer scientists) -- I don’t know if most computer scientists are prejudiced against African-American students because I’ve literally never seen them interact with one.
It’s worth noting that there are a lot of other subtleties in detecting discrimination which have nothing to do with small sample size and which this model doesn’t capture (see the intro to this paper for a brief, clear introduction) but I think small sample size is probably the biggest challenge in the individual-human-experience-setting, so it’s what I focused on here.
What should we do instead?
So it isn’t useful to tell someone that they can’t be sure their experience is due to discrimination, because even in cases when a large amount of discrimination is occurring, people often won’t observe the data to conclusively rule out other factors. What should we do instead?
Here’s one thing I don’t think we should do: assume that discrimination is occurring every time a minority says they think it might be. (I do think we should assume they’re telling the truth about what occurred). The solution to uncertainty and bad data is not to always rule in favor of one party, since it creates perverse incentives and people’s lives get wrecked both by discrimination and by allegations of discrimination. Instead:
- Recognize the severity of the problem that minorities deal with. It’s not that they hallucinate discrimination everywhere or are incapable of logical thinking or rigorous standards of proof. It’s that proving discrimination from anecdotal experience is frequently an extremely difficult statistical task. Also, it’s exhausting to continually deal with the unprovable possibility of discrimination: to wonder, every time something doesn’t work out, if some subtle injustice was at play.
- Use common sense. Statisticians call this “a prior”: ie, you let your prior knowledge about how the world inform how you interpret the data. So, for example, if you hear someone refer to a black student as “articulate” or a female professor as “aggressive”, you don’t need to hear one hundred more examples to suspect prejudice may be at play. Your prior knowledge about how those adjectives are used helps you conclude discrimination more quickly. (I suspect that one reason female judges are more inclined to rule in favor of discrimination suits is because they have different prior beliefs about how common discrimination is.)
- Aggregate data. If one person’s experience doesn’t give you enough data to rule out other factors, aggregate experiences. Class-action lawsuits are an essential means of going after discriminatory employers for this reason. Climate surveys within departments are another example, as is publishing systematic salary gap data (as Britain now does). The sexual assault reporting system Callisto, which aggregates accusations of assault against the same accuser, is based on a related idea, as I’ve discussed.
- Conduct workplace audit studies. This idea is kind of crazy and might get you fired, but here it is: if it’s hard to prove discrimination because there are too many other factors at play, keep the other factors constant. Here are some examples:
- When a female employee says something in a meeting and people ignore it and then a male employee says the exact same thing and gets a more positive response, we’re more convinced that’s discrimination. (There are a hilarious number of Google results for that phenomenon, by the way.)
- A few years ago, I spent a few weeks emailing the NYT’s technical team and getting no response; finally I asked my boyfriend to send them the exact same question, and they immediately responded.
- Or take this recent case, where a male and female employee switched their email accounts and were treated dramatically differently.
All these examples feel like compelling evidence of discrimination because it’s hard to pin the different outcome on extraneous factors; everything except minority status remains the same.
So, could you do this in your workplace? More and more interactions occur online, making it easier to switch identities: for example, you could imagine switching Slack accounts for a week. Obviously there are 14 million ways this could go wrong, but drop me a line if you try it.
So, could you do this in your workplace? More and more interactions occur online, making it easier to switch identities: for example, you could imagine switching Slack accounts for a week. Obviously there are 14 million ways this could go wrong, but drop me a line if you try it.
Footnotes:
[1] This is easily extended to binary outcomes: Y ~ Bernoulli(sigmoid(X * beta + noise))