Here’s an interaction you might’ve participated in:
Member of minority group: I just had [negative interaction] with John. I don’t think he would’ve done that if I hadn’t been a minority.
Listener: That sucks. But...how do you know it was because you were a minority? Maybe he was just having a bad day or he was really busy or …
The negative interaction might be, say, that John talked down to them or didn’t include them on a project. The listener’s reaction is totally reasonable and well-intentioned (at least, I hope it is, because I’ve had it myself). Sometimes it isn’t even said out loud; the listener just thinks it. Here I argue that this reaction is not the most useful one. I explain why, both in English and in math, and then I suggest four more useful reactions.
The problem with this reaction is not that it’s false. It’s that it’s obvious. If a minority tells you about something bad that happened to them, you can almost always attribute it to factors other than their minority status. (Throughout this essay, I’ll refer to negative behavior that’s due to someone’s minority status as “discrimination”.) Worse, this uncertainty will persist even if the discrimination occurs repeatedly and is quite significant. The core reason for this is that human behavior is complicated, there are lots of things that could explain a given interaction, and in our lives we observe only a small number of interactions. Because it is so hard to rule out other factors, individual discrimination suits have notoriously low success rates.
Let’s be clear: I’m not saying you can never prove discrimination from someone’s individual experience. Obviously, there some experiences which are so blatant that discrimination is the only explanation: if someone drops a racial slur or grabs their female coworker by the whatever, we know they’re a president bigot. But, in today’s workplaces, problematic discrimination is rarely so overt -- hence the term “second generation” discrimination. Here’s a picture:

Here’s a simple mathematical model that formalizes this idea. If you don’t like math, feel free to skip to the “What should we do instead” section. Let’s say the result of an interaction, Y, depends on a number of observable factors, X, one of which is whether someone’s a minority. Specifically, let:
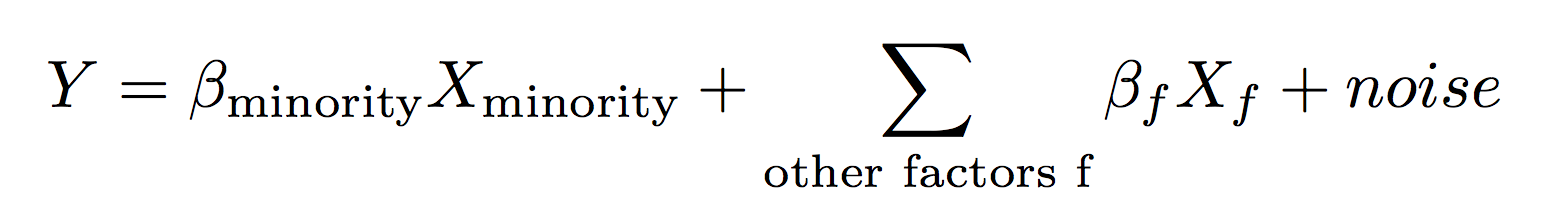
where beta is a set of coefficients describing how much each factor matters, and noise is due to random things we don’t observe. So, for example, Y might be your grade on a computer science assignment, X might include factors like “does your code produce the correct output” and “are you a minority” and noise might be due to stuff like how quickly the TA is grading [1].
If we want to know whether there’s discrimination, we need to figure out the value of betaminority: this will tell us whether minorities get worse outcomes just for being minorities. We can infer this value using linear regression, and importantly, we can also infer the uncertainty on the value.
Here’s the problem. When you do linear regression on a small number of datapoints (which is all a person has, given that they don’t observe that many interactions) you’re going to have huge uncertainty in the inferred values. To illustrate this, I ran a simulation using the model above with two groups, call them A and B, each half the population. I set the parameters so there was a strong discrimination effect against B. Specifically, even though A and B are equal along other dimensions, the average person in A will be ranked higher than about two thirds of people in B, due solely to discrimination; if you look at people in the top 5%, less than a third will be B. So this is enough discrimination to produce substantial underrepresentation. But when we try to infer the value of the discrimination coefficient, we can’t be sure there’s discrimination. In the plot below, the horizontal axis is how many interactions we observe; the blue area shows the 95% confidence interval for the discrimination coefficient (with negative values showing discrimination against B); the black line shows a world with no discrimination.
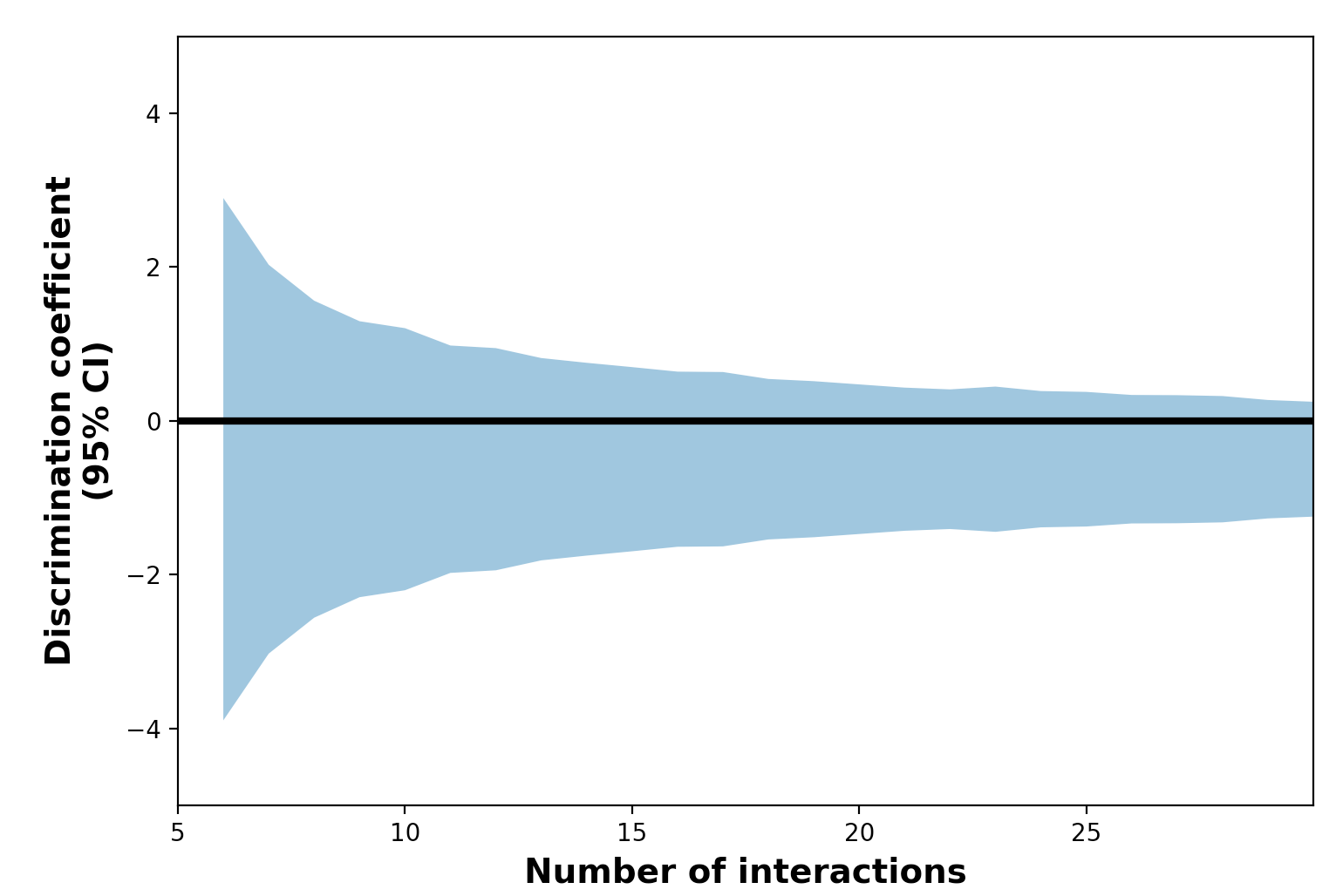
The important point being that the blue shaded area overlaps 0 -- meaning no discrimination is possible -- even if you have literally dozens of interactions, which is way more than you often have. (For fewer than about 5 interactions, the errorbars just blow up and you can’t even graph it.) You can alter simulation parameters or simulate things slightly differently, but I don’t think you’ll change the basic point: you can’t infer effect sizes on sample sizes this small with any confidence.
This model also illustrates some features which make concluding discrimination harder. For example, our errorbars will be larger if other features in X are correlated with being a minority. (“No no, I didn’t promote him because he’s a man. I promoted him because we work well together because we always go out to dinner together / play basketball together / he sounds so much more confident. Well, yes, my wife says I can’t go out to dinner with women…”) Also, your errorbars will be larger if you’re observing repeated interactions from the same person. (If you’re trying to compare your treatment to that of a single coworker, it’s even harder to be sure if it’s because you’re a minority or because of one of the innumerable other ways in which you’ll inevitably differ.) Last, you’re going to be in even more trouble if your minority is a very small fraction of the population whose interactions you observe (say, computer scientists) -- I don’t know if most computer scientists are prejudiced against African-American students because I’ve literally never seen them interact with one.
It’s worth noting that there are a lot of other subtleties in detecting discrimination which have nothing to do with small sample size and which this model doesn’t capture (see the intro to this paper for a brief, clear introduction) but I think small sample size is probably the biggest challenge in the individual-human-experience-setting, so it’s what I focused on here.
What should we do instead?
So it isn’t useful to tell someone that they can’t be sure their experience is due to discrimination, because even in cases when a large amount of discrimination is occurring, people often won’t observe the data to conclusively rule out other factors. What should we do instead?
Here’s one thing I don’t think we should do: assume that discrimination is occurring every time a minority says they think it might be. (I do think we should assume they’re telling the truth about what occurred). The solution to uncertainty and bad data is not to always rule in favor of one party, since it creates perverse incentives and people’s lives get wrecked both by discrimination and by allegations of discrimination. Instead:
- Recognize the severity of the problem that minorities deal with. It’s not that they hallucinate discrimination everywhere or are incapable of logical thinking or rigorous standards of proof. It’s that proving discrimination from anecdotal experience is frequently an extremely difficult statistical task. Also, it’s exhausting to continually deal with the unprovable possibility of discrimination: to wonder, every time something doesn’t work out, if some subtle injustice was at play.
- Use common sense. Statisticians call this “a prior”: ie, you let your prior knowledge about how the world inform how you interpret the data. So, for example, if you hear someone refer to a black student as “articulate” or a female professor as “aggressive”, you don’t need to hear one hundred more examples to suspect prejudice may be at play. Your prior knowledge about how those adjectives are used helps you conclude discrimination more quickly. (I suspect that one reason female judges are more inclined to rule in favor of discrimination suits is because they have different prior beliefs about how common discrimination is.)
- Aggregate data. If one person’s experience doesn’t give you enough data to rule out other factors, aggregate experiences. Class-action lawsuits are an essential means of going after discriminatory employers for this reason. Climate surveys within departments are another example, as is publishing systematic salary gap data (as Britain now does). The sexual assault reporting system Callisto, which aggregates accusations of assault against the same accuser, is based on a related idea, as I’ve discussed.
- Conduct workplace audit studies. This idea is kind of crazy and might get you fired, but here it is: if it’s hard to prove discrimination because there are too many other factors at play, keep the other factors constant. Here are some examples:
- When a female employee says something in a meeting and people ignore it and then a male employee says the exact same thing and gets a more positive response, we’re more convinced that’s discrimination. (There are a hilarious number of Google results for that phenomenon, by the way.)
- A few years ago, I spent a few weeks emailing the NYT’s technical team and getting no response; finally I asked my boyfriend to send them the exact same question, and they immediately responded.
- Or take this recent case, where a male and female employee switched their email accounts and were treated dramatically differently.
All these examples feel like compelling evidence of discrimination because it’s hard to pin the different outcome on extraneous factors; everything except minority status remains the same.
So, could you do this in your workplace? More and more interactions occur online, making it easier to switch identities: for example, you could imagine switching Slack accounts for a week. Obviously there are 14 million ways this could go wrong, but drop me a line if you try it.
So, could you do this in your workplace? More and more interactions occur online, making it easier to switch identities: for example, you could imagine switching Slack accounts for a week. Obviously there are 14 million ways this could go wrong, but drop me a line if you try it.
Footnotes:
[1] This is easily extended to binary outcomes: Y ~ Bernoulli(sigmoid(X * beta + noise))
Saw your article in Wired, nice job, and found your blog. This is a good example of what you were talking about, how to ethically ascribe meaning to results. We all recognize linear least squares is generally a bad approach, as you address at the end, but even with better results the issue remains that there's always uncertainty in the answer. In physics, where I work, "Oh well, maybe the density coefficient isn't quite 1g/cm^3 but the application tolerances can adjust," but in humanities people may not appreciate the tolerances. Worse, for your field is that in physics we know the approximations and inaccuracies of our model (your other coefficients), but you have less to build on.
ReplyDeleteWhat probability distribution and amplitude did you give the noise in this example, Gaussian?
I think there are a lot of publications in this area - both formal an informal studies that are very powerful, but also some that are weak. Sometimes judgement is hard when studies go against personal experience though. I am a White Man and have rarely seen evidence of discrimination (although some of the few cases I have knowingly seen have been pretty horrific) and never have I knowingly seen it in the workplace. A lot of these anecdotes didn't do a lot to convince me (and generally I will still believe the best of people until there is stronger evidence). The studies that convinced me workplace discrimination is a problem is the studies where identical C.Vs get sent out and the response rates for names strongly associated with different ethnicities are compared. Being able to do pairwise comparisons whilst holding everything else constant makes for powerful comparisons. Quite possibly because I am not well read enough I have never seen positive results for this approach to identify sex discrimination though. Somewhat playing the devil's advocate, even the examples you give of women receiving a different response to the same statement/suggestion to the response a man receives can be difficult as there is a question as to is it due to two people suggesting it or is it because a man does so.
ReplyDeleteAt the aggregate level thinks might be more straightforward but it is still not easy and there are a couple of difficulties (well difficuties for me - I am still new to the topic and finding my way around) that you skip over (short article so nothing wrong with focusing on the most important points).
The first issue is correlation. How do you tell the difference between discrimination (say based on ethnicity or gender) and discrimination based on something correlated with ethnicity or gender? With large enough data sets well split between men and women you can see if height, for example, can better play a role in predicting salary and whether it can explain differences within male and female groups. The problem is that there is no shortage of variable like this when you search for them and the more thorough we are in accounting for other explanations the greater the uncertainty is on any measure associated with the simple minority grouping. I used height as an example as it would still (by common moral standards) still be considered discriminatory but just that the grouping would be misidentified.
The other big issue I am trying to get my head round is how granular an analysis should be. A big organisation may have a thousand different teams within it and some of them will certainly look discriminatory, just through chance. I am having trouble working out how much to infer about an organisation from those teams that are significant.
The more I think through the (limited) data I have the more trouble I have (is this normal?). If I compare salaries, is this identifying discrimination or past discrimination? If someone was held back in another company for 10 years before joining their current employer it would show up in their current salary (even if the current employer treated them the same way as anyone else with their level of senior experience). My approach was to look at times between promotions and rate of pay increase instead - even then it gets very complex by different patterns of different groups moving between companies. On the other hand the paper that you linked to seems like it might be useful for some of my problems (if a group performs better in appraisal following a promotion than another group, does it mean the bar was set higher for them?).
I certainly appreciate blogs like this though - I feel that having an open discussion about what aspects of the problem can be addressed objectively and with some high confidence bounds is a big step forwards. I am not sure I feel I know the subject better but maybe I am a slightly more informed type of perplexed.
{Download} $12,234 within 2 months Casino Software?
ReplyDeleteLet me tell it straight.
I don't care about sports. Shame on me but I don't even know the basketball rules.
I tried everything from forex & stocks to internet marketing and affiliate networks.. I even made some money but then blew it all when the stock market went south.
I think I finally found it. Grab It TODAY!
There's shocking news in the sports betting industry.
ReplyDeleteIt has been said that any bettor needs to see this,
Watch this now or stop placing bets on sports...
Sports Cash System - Robotic Sports Betting Software
Everyone has had some thought, good or bad, nag at them from time to time. But to be obsessive means that you can’t get the distressing thoughts out of your mind no matter how hard you try. These obsessions are usually negative in nature. They can be violent thoughts or even thoughts about germs and sanitation. These thoughts often cause you to be unproductive and withdrawn from society.
ReplyDeletehttps://healthandfitness2020.com/obsessed-definition-obsessed-meaning-in-english/
https://bit.ly/2BkFOVm
Hello everyone, my name is ALFREED SIANG i am here to say a big thank you to my doctor DR OLU who helped me enlarge my penis.i have never had a happy relationship in my life because of my inability to perform well due to my small penis, due to frustration,i went online in search of solution to ending my predicament and than i came across testimony on how DR OLU has helped them, so i contacted him and he promised to help me with penis enlargement,i doubted at first but i gave him a trial and he sent me the product which i used according to his prescription and in less than a week,i saw changes in my penis and it grow to the size i wanted and since then,i am now a happy man and no lady complains again about my penis.if you also need the services of my doctor,you can also contact him on his email..drolusolutionhome@gmail.com or his whataspp is +2348140654426
ReplyDeleteThank you for this post.This is very interesting information for me.
ReplyDeletepersuasive essay topics.
Very positive photos. Thank you for the article. I know what you need is a homework writing service.
ReplyDeleteiphongthuynet
ReplyDeleteiphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
iphongthuynet
Great Post, Dial Printer Repair Services Number Ireland +353-1442-8988 & get online support for all printer brands like HP, Brother, Epson, Canon etc. we fix printer issues like setup, install, drivers, wifi network connectivity, paper jam, not printing etc in Ireland get more information visit here Printer Repair Services Number Ireland
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteI feel that having an open dialogue about what factors of the problem may be addressed objectively and with a few high confidence bounds is a massive step forwards. A large organization might also have 1000 special groups inside it and some of them will sincerely look discriminatory, just through danger. Assignment Writing
ReplyDeleteAnti-discrimination laws make it unlawful for a business to make unfriendly work move against you in the event that you are an individual from a secured class, or classification of people. Not a wide range of segregation are secured under the government hostile to separation laws. Likewise, while the government laws secure you against working environment segregation, it is regularly exceptionally hard to demonstrate that separation happened. mobile app development services Colorado
ReplyDeleteCALL NOW
ReplyDeleteCall now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280Call now 09336801280 call boy Play boy service provider all India ki all City mey services available full secret service provider koi Dhokha dhadhi nhi full maza Masti key saath pasaa kamye (50000 sey 90000 per month)call me 09336801280
ReplyDelete
ReplyDeleteClass College Education training Beauty teaching university academy lesson teacher master student spa manager skin care learn eyelash extensions tattoo spray
Get the assignment solution for the target and positioning marketing topic. If you are facing any difficulty in making your Target And Positioning Marketing coursework as we recognize a major number of students find it tough to make their STP assignment due to inadequate knowledge of marketing management, then you can ask our experts for targeting and positioning homework assistance.
ReplyDeleteAt Best CDR Writing, we are providing the expert CDR Writing services at an affordable cost. We have a team of professionals which will deliver the best quality work.
ReplyDeleteGreat article. Agree with you.
ReplyDeleteดูหนังออนไลน์
ดูหนัง
ดูหนังออนไลน์เต็มเรื่อง
ดูหนังออนไลน์ hd
ดูหนังออนไลน์ฟรี
Did you try to set up the HP printer via 123.hp.com.setup and failed? This can be frustrating if you are not able to set up your Printer. Well, you can seek help from the technical experts. This option will help you easily to know the process of setup. You simply have to connect with the experts and ask them for the solution. Professionals will guide you step by step by mentioning the details of each part. Apply the steps and get your HP printer properly setup. The service is available all round the clock, 24*7 for the customers.
ReplyDeleteThanks for sharing this post, We are a top- level, and trustworthy third-party tech support provider, having immense years of technical experience and capability of solving all common errors related to brother printer. When you experience Brother printer offline error, our live printer experts are skillfully proficient for bringing back from Brother Printer offline to online in the proper ways. Normally, this technical glitch takes place, when you give a printing command to your brother printer to print the documents. Our techies are technically known for resolving brother printer offline error.
ReplyDeleteTo activate the Roku tv account without the credit card, here are the steps that you need to follow:
ReplyDelete1.First of all, turn on the Roku TV or the device and also refer the setup guide that came with it
2.So, you’ve to choose a language and link to the Wi-Fi Network
3.Also select the finest resolution for the gadget
4.Once the process is done, you’ll have to activate the Roku device by using the code
5.Open a web browser and hover to the Roku.com/link website
6.Now enter the code and click the submit option found on the page
7.The TV or the device gets activated and begin to add all the platforms
Well, if you are facing any constraints while performing the Roku account setup without using a credit card, then you need to skip the process right away and look for alternatives elsewhere
Also, call the support team to fix off the issues at the right time. The panel is well versed in providing the best alternatives
When I attempt to open QuickBooks desktop, I am experiencing QuickBooks error 3371 status code 11118. This error code is displaying on the screen, so I am not able to work on my QuickBooks. Due to the occurrence of this error code, my QuickBooks could not load the license data. I don’t have bookkeeping knowledge to find out the real reasons of this error code and apply the appropriate solutions to fix this error code. I am asking from someone to suggest the best ways to fix this error code. So anyone can suggest the simple ways to solve this error code as soon as possible.
ReplyDeleteMantapppppppp
ReplyDeleteYour article release are more fresh and impressive for us. This is a tremendous topic niche thanks for sharing this informative info. I will go to your article posts regularly for some contemporary posts. Please keep sharing more such blog. online reviews of marketing dissertations in london -
ReplyDeleteinteresting hrm dissertation help topics london -
how to write a undergraduate dissertation proposal
Mantaappp bossskuuu
ReplyDeleteLove does not begin and end the way we seem to think it does. Love is a battle, love is a war; love is a growing up. Of all forms of caution, caution in love is perhaps poker online terpercaya the most fatal to true happiness.
ReplyDeleteThese organizations are available with 24*7 customer sponsorship to give minute support to all understudies.
ReplyDeleteAssignment Writing Service
Assignment help
I maintain my financial transactions with the help of QuickBooks, accounting program. I trust on QuickBooks’s functions because this tool is very simple and efficient for keeping and maintaining a record of my accounting and financial transactions in systematic ways. While refreshing bank details, I am facing QuickBooks Online Error 9999. This error code is certainly a major and complicated issue, so I look for QuickBooks expert’s help. Undoubtedly, I am missing some difficult patch for this error code. So please guys share some easy tips for fixing this error code.
ReplyDeleteSarkari Naukri -Get the Latest Sarkari Naukri, Jobs, Vacancy Information. Post office Vacancy, Indian Armay Vacancy, Railway Recruitment.
ReplyDeleteThe article information you have posted is very superb and cleared. The websites you have referred was good. really admin its very informative keep going on thank you. Assignment Help Sydney
ReplyDeleteI am facing problems to complete the downloading process of AOL Gold Desktop. So, I want to take step by step technical guidance for the downloading process. So anyone can share the easy tips to download this software on my computer system.
ReplyDeleteOne very important question to think about is why students should think about Assignment Help services in Malaysia? Why it is important to hire an academic writer for your assignments? This is a good concern to think about because you have to take care of many things while studying in Malaysian universities.
ReplyDeleteAssignment Helper
Your article is very marvelous and brilliant information is reliable. I am satisfied with your every single word share here. Thank you so much for sharing this wonderful blog. Bye and food night. Assignment Writers
ReplyDeleteWhile we are using the other tools, there are no such choices we find like the resume of the downloading and the scheduling of the download. There is also no complete detail of the files with its format and artist detail. When you are downloading the data from this tool, you can view the percentage of the files. It will give you complete detail of the download percentage with the passage of every moment till its 100 % completion.IDM Crack
ReplyDeleteGmail problems and Gmail Not Receiving Emails is one of them. You should continue reading this blog if you are also a victim of the same problems.
ReplyDeleteAt Ascent, we provide the best Fund Administration services to our clients so that they need not juggle between the complexities of the dynamic real estate market. Our subject matter expert will assist you in accounting, finance management, and offers to consult as per the specific needs of real estate funds management.
ReplyDeleteAlways, anywhere and anytime,I feel very comfortable now all to the work of Dr Ebacol,the Herbalist who prepare for me the remedies to my health challenges.i could feel more comfortable when he explained to me how dangerous it's caring Herpes with me getting affected easily with Other sexually transmitted infections. Genital sores increases my risk of transmitting or contracting other sexually transmitted infections, including AIDS.
ReplyDeleteNewborn infection. ...nd a lover who ran into it and had a shock on me after the checkup and develop stroke.
This has been my earnest prayers for the physician therapist to come in with positive solutions to remedies Herpes and most
Bladder problems. ...
Meningitis. ...
Rectal inflammation (proctitis).
I was so scared when he says that because I fou viral infections. I'm now free and I thank God for leading me to see others getting cured with Herbs. I decided to try and found out that the best way I would have done was to get rid of it and give my testimony. Glory to God I became free after I received his medicine from the DHL and applied as instructed. Till date I had no SYMPTOMS nor virus to detect of me, I called him and thankful for what he did,and ask if he could cure my stroke boyfriend,he said yes and did the same preparation to my boyfriend for his stroke and Recovered from it. Nothing is impossible with Herbs IN CURES, you're the next if you will be willing to apply his medicine and instructions on how to manage.
Sickness has no right to dwell on us,you can reach him at his email address
For your immediate response to health
drebacolherbalhome1@gmail.com
Cell number (WhatsApp/calls)
+2348159042641
Configuring the IMAP (Internet Mail Access Protocol) and SMTP (Simple Mail Transfer Protocol) server settings will govern the viewing, receipt, and sending an email. For the first time, you will need to configure the Yahoo Mail server settings in your device in order to start the mailing services.
ReplyDeleteI have good experience with this emailing application service. Now, I want to open my AOL mail messages and folders in Mac Mail. Due to some AOL IMAP Settings problems, I am getting problems to open them appropriately. I have taken online help from AOL technicians, but nothing is successful.
ReplyDeleteVery informative and impressive post you have written, this is quite interesting and i have went through it completely, an upgraded information is shared, keep sharing such valuable information. Fertility Test Singapore
ReplyDeleteIt is possible to maximize your rrr.com login security by using a password sync system that enables you to carry your login credentials with you safely. Though, there are few problems such as unable to send an email, can’t log in to a Roadrunner account, how to attach multiple messages, etc.
ReplyDeleteOur Chicago reference tool is extremely easy use to use. Your time is extremely valuable to us and, thus we have designed the Chicago citation maker in a way that takes least of your time. In case you are sceptical of using our Oxford referencing tool, we would like to mention that the tool has got some amazing benefits for its users. It indicates to the software piece and online tool permitting to format and store references. This is also vital that one go for the proper tool for the research get stuck to that.
ReplyDeleteBeing a reputable writing service provider in UK, MyAssignmenthelp.co.uk assists pupils to attain academic success. Students, who are worried about, ‘who can write my assignment for me?’ should read this article in order to get their answers. We assist students to produce outstanding assignments and meet academic requirements in the best possible manner. Being an efficient online assignment provider in UK.
ReplyDeleteIf you want to reset yahoo mail settings
ReplyDelete, you can get the specialized guidance from our trained technical professionals to reset the yahoo mail settings in the correct ways. Our technical professionals are very experienced to reset the yahoo mail settings in simple ways.
To fix quickbooks error -6190, firstly, you must try to use the QuickBooks install diagnostic tool under the QB tool hub. If you have already tried this method, then you will have to rename the ND and TLG file and add ".OLD" extension name at the back. After that, you will have to open the folder that contains your company file, search for the files with ".ND" and ".TLG" extension names, right-click over them, click rename and then write ".OLD" at their back. Now restart the QuickBooks again and log in to your company file. Hopefully, you have successfully fixed the error 6190.
ReplyDeleteI really appreciate your suggestions and Thanks a lot for sharing a piece of mind blowing information. This is a great blog post thanks for sharing this outstanding information. australia assignment help -
ReplyDeleteassignment help in melbourne -
Assignment Help Adelaide
We are a third party GPS service providers who can assist you fix issues with your Garmin device. Also, our expert team will help with How to update Garmin GPS in a few simple steps. Updating you Garmin GPS is as important as buying it. For your device to keep showing the exact pathways, you must update it to the latest version. Garmin is pretty regular with releasing the latest version to improve the device performance and new maps. You can download the Garmin Express or Garmin Updater and follow the on-screen instructions to install the latest software and maps. To assist you, we have a team who is well-versed with Garmin GPS and troubleshooting the errors that you can face while updating it. Contact us now.
ReplyDeleteThanks for sharing the valuable information. It is my pleasure that I consumed your content and invested my time in it.
ReplyDeleteFix brother scanner
brother control center 4
brother printer offline
brother printer wifi setup
How to connect brother printer to mac
Brother Printer Driver Errors
phdassistance is the best Dissertation writing help available for the students and Education People in UK, USA, UAE, Australia where they can avail PhD Dissertation writing help UK. It does not only provides best Dissertation services to the students residing in UK , USA, UAE but also to the students living outside the country.
ReplyDeletePhD Dissertation Writing Services UK
PhDDissertationEditingHelpUK
PhDDissertationLiteraturrReviewHelp
PhDDissertationEditingServices
PhD Research Topics UK
In my point of view , we should not promote to the discrimination among the human beings , indeed , you should try to united them by our piece of work. Dissertation Writing Service
ReplyDeleteIt was introduced for Windows PCs all versions only but later on within the best and newest versions are also supported with other platforms like MAC, Linux, Vista and now also working on mobiles versions. It will be all in one satisfy up to the very important https://freeprosoftz.com/teamviewer-full-crack-keygen/
ReplyDeleteThanks for giving great kind of information. So useful and practical for me. Thanks for your excellent blog, nice work keep it up thanks for sharing the knowledge. for more information click here: Outdoor Hoarding Advertising Agency in Mumbai
ReplyDeleteCar lease Rent a Car provides Cheap car rental Dubai, car hire and long term car rental Dubai with cheap car rental offers in the UAE on daily, weekly and monthly car rentals.
ReplyDeleteAll queries with respect to your Roku Streaming Device not connecting to Internet can be directed towards our website go.roku.com/connectivity error code 016. and our team of experts will be happy to help you 24/7 @+1-820-300-0340. We also have informative articles regarding device installation and setup, channel activation and troubleshooting.
ReplyDeleteDiva Williams is a creative person who has been writing blogs and articles about cybersecurity. She writes about the latest updates regarding office setup and how it can improve the work experience of users. She articles have been published in many popular e-magazines, blogs, and websites like webroot.com/safe .
ReplyDeleteWriting a Short Essay includes a format, so before you start your first short essay be sure about its format. Learn more read the blog.
ReplyDeleteCold weather! Some are very useful!
ReplyDeleteThanks for reading this article
other sites are also good.
netbalancer activation code
Thanks for sharing the info! Are you looking for Microsoft office 365 install on the Computer Windows, iOS and PC, Tablet have any kind of technical issues can visit on the web www.office.com/setup and login your Microsoft account with your correct login credential i.e. username and password need more help can connect our technical assistant engineers can help you all anywhere.
ReplyDelete
ReplyDeleteThanks for sharing the useful information. You have mentioned all essential points for getting Assignment Help easily. Epson printer error code 0x97
I really appreciate your smart writing as the design of your blog.
ReplyDeleteIs it a payment issue, or have you treated yourself?
In any case, the best thing about writing remains.
It is rare to see such a beautiful web page like this one day.
dllkit pro crack
fabfilter pro q crack
parallels desktop activation key crack
siemens solid edge crack license key
I really appreciate your content good job!
ReplyDeleteWhy my Brother printer in error sate? is reason? I have check all connected peripherals completely also I have checked drivers message.
Thankyou For Sharing Useful Details.
ReplyDeleteJcpenney Sephora Gift Card Balance Check Sephora Gift Card Balance
Maharshi Dayanand Saraswati University BCom Time Table 2021 Students Can Check 1st 2nd 3rd Year BCom Routine 2020-2021.
ReplyDeleteDo you need an urgent loan of any kind? Loans to liquidate debts or need to loan to improve your business have you been rejected by any other banks and financial institutions? Do you need a loan or a mortgage? This is the place to look, we are here to solve all your financial problems. We borrow money for the public. Need financial help with a bad credit in need of money. To pay for a commercial investment at a reasonable rate of 3%, let me use this method to inform you that we are providing reliable and helpful assistance and we will be ready to lend you. Contact us today by email: daveloganloanfirm@gmail.com Call/Text: +1(501)800-0690 And whatsapp: +1 (315) 640-3560
ReplyDeleteNEED A LOAN?
Ask Me.
Your writing skills greatly impressed me, as well as the clever blog structure.
ReplyDeleteIs it a payment issue or do you change it yourself?
However, if you stop writing in high quality, it's hard to see a good blog these days.
beyond compare
cardrecovery
smart hindi typing master crack
easeus partition master crack
In case you want your pubg license key crack for pc ex-lady friend or ex-boyfriend to come crawling back to you on their knees (even though they are dating anyone else IDM Crack now) you ought to watch this video
ReplyDeleteproper away.
Is your Epson printer delivering the black pages? No worries, we will help you fix it. We are a team of certified printer technicians who can resolve the Epson printer not printing problem and many such errors with ease. The problem occurs when the ink is low or dried up, paper jammed in the Epson machine, clogged printhead, using non-recommend paper for printing, etc. Troubleshooting the problem will require you to begin fixing from the root level like ensuring ink in the cartridge, cleaning the printhead with a clean towel or paper, and always using the recommended paper or another component. However, we always recommend following these steps under the expert’s guidance. Contact the Epson support helpline number and get immediate assistance.
ReplyDeleteNRI Legal Advisors are the best and professional NRI property lawyers in Hyderabad having a professional NRI lawyers team and also provide you the best NRI legal consultation to you. For more info, you can also visit the official website of NRI legal advisors India and schedule a free call back for you. You can also find more information about how to file divorce in India with the help of the best blog written over the official website law credo.
ReplyDeleteHey, Your blog is very informative. It is nice to read such high-quality content. Dissertation providers deliver quality content related to your Dissertation. We also assist in law dissertation help. Epson printer offline
ReplyDeleteGreat Article. Thank you for sharing! Really an awesome post for everyone.
ReplyDeleteIf are stuck whereas AOL Desktop Error Message Code 104, then you will directly contact the AOL Experts. They're accessible 24/7 hours; be happy to contact the Emails Customer Care Team. Our professionals are well-certified and trained to resolve the common problems associated with the AOL Desktop Gold. Are you continue to trying to find instant help? If yes, then consider us and find the most effective services as soon as doable.
Android Apks - is a place where you can fiAndroid Apks - is a place where you can find paid best android apk apps games to download free full version for mobile, tablets.
ReplyDeleteapk here du recorder
Contact Facebook if you have problem with the interaction of reset email and password?
ReplyDeleteIf you plan to reset the email and password of the Facebook account, you are expected to sign in to your account and then navigate the personal area. Starting there, you will get the contact area, so you can reset your email from here. You can get the password tab to reset the password. Contact Facebook if you have problem regarding it.
Commonly what happens is we attempt to print a report on our brother printers yet can't do it because of error that we are unconscious of and the screen shows "printer in error state". Even subsequent to giving it a shot various occasions we neglect to determine it.At such a period we get bothered with our printers and are totally disturbed at what to do next to make it work. It is extremely simple to set up for the individuals who know How to Fix brother Printer In Error State however on the off chance that you can't do it.
ReplyDeletehow do i fix printer in error state
I am here to give my testimony about Dr Ebhota who helped me.. i want to inform the public how i was cured from (HERPES SIMPLEX VIRUS) by salami, i visited different hospital but they gave me list of drugs like Famvir, Zovirax, and Valtrex which is very expensive to treat the symptoms and never cured me. I was browsing through the Internet searching for remedy on HERPES and i saw comment of people talking about how Dr Ehbota cured them. when i contacted him he gave me hope and send a Herbal medicine to me that i took for just 2 weeks and it seriously worked for me, my HERPES result came out negative. I am so happy as i am sharing this testimony. My advice to you all who thinks that there is no cure for herpes that is Not true just contact him and get cure from Dr Ebhota healing herbal cure of all kinds of sickness you may have like (1) CANCER,(2) DIABETES,(3) HIV&AIDS,(4) URINARY TRACT INFECTION,(5) CANCER,(6) IMPOTENCE,(7) BARENESS/INFERTILITY(8) DIARRHEA(9) ASTHMA(10)SIMPLEX HERPES AND GENITAL(11)COLD SOREHERPES. he also cure my friend from cervical cancer Email: drebhotasoultion@gmail.com or whatsapp him on +2348089535482
ReplyDeletehttps://cracksz.com/parallels-desktop-16-crack/
ReplyDeletehttps://cracksz.com/tweakbit-driver-updater-2-2-4-crack/
https://cracksz.com/minitool-power-data-recovery-9-0-crack/
https://crackcut.com/microsoft-office-2019-product-key/
https://crackcut.com/divvy-crack/
https://crackcut.com/xlaunchpad-1-1-8-822-crack/
https://cracktips.com/spyhunter-crack/
https://cracktips.com/acronis-true-image-crack/
https://cracktips.com/serif-affinity-designer/
Great ! I appreciate your consideration guidance, help, time.
ReplyDeleteFonepaw Iphone Data Recovery
Wintous Benterprise Crack
Blue Cloner Crack
Anytrans Windows 10 keygen
microsoft office Crack free download
divvy Crack free download
xlaunchpadCrack free download
In our view, the Glock 43 is said to be one of the Best Custom firearms. If you want to make one, you can visit an online portal to get the right parts and accessories. Once you get all of them, make sure that they are legal. While shipping these elements, transfer them to a guy who has the Federal Firearms license. You can never get it directly to your home. Approach a gunsmith and frame a proper blueprint. So, Get the work done in a few minutes!
ReplyDeleteHiring professional Packers and Movers in Delhi NCR. Packers and movers in NCR makes things essential next to that client would discover the chance to find a New solutions Om International Packers and Movers
ReplyDeleteThanks for your article. It was well written and I really enjoyed it. I also want to share some information to those who are looking for Online GST Registration Service In Delhi.
ReplyDeleteThen DigitalCA helps you to register your Company, manage your business, and legal compliance in Delhi Noida. Trade Mark Registration, ESI Registration, PF Registration, GEM Registration, Company Incorporation, GST Registration, Accounting, Import-Export Code
Nice. I am really impressed with your writing talents and also with the layout on your weblog. Appreciate, Is this a paid subject matter or did you customize it yourself? Either way keep up the nice quality writing, it is rare to peer a nice weblog like this one nowadays. Thank you, check also event management and conference bio example
ReplyDeleteNice message, I am reviewing this blog all the time and it impressed me a lot!
ReplyDeleteVery useful information, especially the last step: I tend to deal with this kind of information. I am looking for this
Extra information for a long time. Thank you and good luck.
avast secureline vpn license key
intellij idea crack
eset smart security crack
nordvpn crack
ytd video download pro crack
freemake video converter crack
If you are looking for bloggers, please let us know.
ReplyDeleteYour position is very good, I think I will have a great advantage.
If you want to lose some weight, I'm happy.
Write something about your blog in exchange for my link.
If you are interested, please email me, thanks!
electrax vst
truecaller apk crack
wondershare mobiletrans crack
hma pro vpn crack
ntlite crack
malwarebytes anti malware crack
Nicely written & done.
ReplyDeleteI started writing in the last few days and realized that lot of
writers simply rework old ideas but add very little of value.
It’s fantastic to read an informative post of some genuine value to myself and your other followers.
It is on the list of things I need to replicate as a new blogger.
Reader engagement and content quality are king.
Some terrific ideas; you’ve most certainly managed to get on my list of blogs to watch!
Carry on the terrific work!
Well done,
Cheryl.
nexus vst crack
You won’t hear back right away from most contacts. Conference speakers and organizers tend to be busy folks. Give it a few days, then send a follow-up note. If they don’t reply before the conference, don’t take it personally. virtual edge and thank you for your advice i really appreciate it
ReplyDelete"Regression" is a statistical method used in finance, investing, and other disciplines that attempts to determine the strength and character of the relationship between one dependent variable and a series of other variables.
ReplyDeleteoffice.com/setup
How a user can get Cash.app/help
ReplyDeleteAs a cash app user you may face some issues while you are using the cash app these issues may include unable to access the cash app account, facing issues if you did the wrong payment, unable to receive money from senders, and many more. Users will get all solutions from Cash.app/help page.
Is the Google server down cause of the not working issue?
ReplyDeleteAssuming the Google server down, clearly, you will get Gmail not working issue. Aside from this, this issue likewise produced, in the event that you have introduced wrong augmentations or additional items on your program or you introduced some unacceptable application on your gadget. Thus, when you get this issue, you need to check every one of the things cautiously.
ReplyDeleteDoes a cash app protect my account from getting a Cash app hacked?
Many times, people are unaware of the scamming practice and start to make payments to an unknown number. But if your payment has been failing multiple times then it must be done by the cash app itself to protect your account from hacking. If you want to fix this issue then we suggest you contact the cash app support team and ask for a solution to the Cash app hacked account
Assignment Help in Germany
ReplyDeleteThetutorshelp.com is popular among the student of Germany for providing best quality assignment help Germany online. As an online assignment helper, subjects such as engineering, management, mathematics, law, language, economics, and finance, to mention a few.https://www.thetutorshelp.com/assignment-help-germany.php
Assignment Help in New Zealand
ReplyDeleteGet custom writing services for Assignment Help in New Zealand &New Zealand Homework help. Our New Zealand The tutors help are available for instant help for New Zealand assignments https://www.thetutorshelp.com/new-zealand.php
Assignment Help in Germany
ReplyDeleteGet custom writing services for Assignment Help in Germany & Germany Homework help. Our Germany The tutors help are available for instant help for Germany assignments. https://www.thetutorshelp.com/assignment-help-germany.php
Assignment Help in Qatar
ReplyDeleteGet custom writing services for Assignment Help in Qatar & Qatar Homework help. Our Qatar The tutors help are available for instant help for Qatar assignments. https://www.thetutorshelp.com/assignment-help-qatar.php
Assignment help in Bahrain
ReplyDeleteGet custom writing services for Assignment Help in Bahrain & Bahrain Homework help. Our Bahrain The tutors help are available for instant help for Bahrain assignments. https://www.thetutorshelp.com/assignment-help-bahrain.php
Assignment Help in Egypt
ReplyDeleteGet custom writing services for Assignment Help in Egypt & Egypt Homework help. Our Egypt The tutors help are available for instant help for Egypt assignments https://www.thetutorshelp.com/assignment-help-egypt.php
Assignment Help in Vietnam
ReplyDeleteGet custom writing services for Assignment Help in Vietnam & Vietnam Homework help. Our Vietnam The tutors help are available for instant help for Vietnam assignments https://www.thetutorshelp.com/assignment-help-vietnam.php
Assignment Help in Turkey
ReplyDeleteGet custom writing services for Assignment Help in Turkey & Turkey Homework help. Our Turkey The tutors help are available for instant help for Turkey assignments https://www.thetutorshelp.com/assignment-help-turkey.php
B2B marketers said that their future events will include digital capabilities They also share that B2B marketers will need much more from their technology providers to create hybrid events that deliver value and revenue. virtual edge and thank you letter for attending conference
ReplyDeleteThis article content is really unique and amazing.
ReplyDeleteBA 2nd year time table
Have a nice blog! Is your theme a custom theme or did you download it somewhere?
ReplyDeleteA design similar to yours with a few simple settings
You really make my blog shine.
Please let me know where you got your theme from.
hide all ip crack
smadav pro crack
3utools crack
wondershare filmora crack
cleanmymac crack
Have a nice blog! Is your theme a custom theme or did you download it somewhere?
ReplyDeleteA design similar to yours with a few simple settings
You really make my blog shine.
Please let me know where you got your theme from.
eset nod32 antivirus crack
eset internet security crack
simlab composer crack
hard disk sentinel pro crack
zbrush crack
Hey Nice Blog!! Thanks For Sharing!!! Wonderful blog. Its really helpful for me. Let me tell you that, If you are looking for Affordable R.O. Water Purifier in Gurgaon. Then See Gol Company is the Best R.O. Water Purifier Supplier in Gurgaon. Call us - 9873 804 244
ReplyDeleteNice Blog !
ReplyDeleteIn case you are looking for the best solutions to solve QuickBooks Error 136, Our team is always available to give you the best assistance at an affordable rate.
Best Outdoor Umbrella For High Winds usually put in outdoors the home in garden locale you will also use on accommodations at roof prime for batter atmosphere. That is certainly lengthy expression product on the grounds that it constructed with polyester material and steel produced stand. The movable steel stand presents you correct sunshine light safety. One can also sustain rest outside the house your home with pals and family in case you have this. The made cloth doesn’t make it possible for and heat and rays under the shade of umbrella.
ReplyDeleteWow, What an Outstanding post. I found this too much informatics. It is what I was seeking for. I would like to recommend you that please keep sharing such type of info.If possible, Thanks.
ReplyDeleteIExplorer Crack
RoboForm Crack
Pc License Keys
Learn here how you can setup HP Envy 4520. Whole procedure with step by step guide available here : HP Envy 4520 Wireless Setup
ReplyDeletegood to see here this article.
ReplyDeletebookzz
jcpenney associate kiosk
tcs webmail
liteblue login
tutorialswebonline
Coupon2deal offers to search for Great Coupons or Deals and Save Huge. Get the Best Money-Saving Discounts, Offers, Promo Codes, Freebies, etc from Coupon2deal.comLight In The Box Coupon
ReplyDeleteAlamy Promo Code
eBay Coupon
Amazon Promo Code
H&R Block Coupon
Would you choose to download films from YouTube at swiftest speed how can we do if you can get this do the job proficiently you by using YTD Crack this software possess a specific power to download. YouTube films from YouTube easy and in quickest velocity also you can not convert them online to any file formats you can download YouTube films in any resolution even 4K this will offer you is suitable with all the windows versions are on the market even Windows 10 or Windows XP you’re able to efficiently use this software on the grounds that it's got a straightforward man who offers the consumer to apply this software absolutely soon and this will make she used to use this software awfully quicker.
ReplyDeleteAndroid Apks - is a place where you can fiAndroid Apks - is a place where you can find paid best android apk apps games to download free full version for mobile, tablets.
ReplyDeletecamera fv-5 pro apk v3.32 full premium
google 3434
ReplyDeletegoogle 3435
google 3436
google 3437
google 3438
google 3439
Our Free Game Helps Young People Ages 16 To 21 Develop Work Readiness Skills From Home. Embark On Your Virtual Journey Around The Globe And Try Out Jobs In Growth Industries Now! Life Skills Curriculum. Global Youth Job Skills. Holistic Approach.
ReplyDeletefullcrackedpc.com
vsthomes.com
Enscape 3D Crack
Avocode Crack
DVDFab Video Downloader Crack
SpyHunter Crack
A user can touch with our Roadrunner customer service via phone or online medium in email for solve their query. Our customer service is always available for help.
ReplyDeleteWe the team of high-class professionals provides support for Bellsouth login issues. So, if you are unable to log in despite entering the right details, then we are there to help you out.Visit our official website to know more.
ReplyDeleteNuce Blog !
ReplyDeleteOur team at QuickBooks Customer Service is capable of fixing all your technical queues within 20 minutes in extraordinary circumstances.
Very Useful And Very Creative Article Which Is Post By Site Owner ThankYou So Much Sir.
ReplyDeleteBest High DA-PA Dofollow Comment Backlink Sites List.
Comment Backlink Sites List.
Nice Post !!!
ReplyDeleteCall Girls In Ambernath !!
Call Girls In Jalna !!
Call Girls In Ichalkaranji !!
Call Girls In Parbhani !!
Call Girls In Chandrapur !!
Call Girls In Ahmednagar !!
Call Girls In Bhiwandi !!
Call Girls In Latur !!
Call Girls In Jalgaon !!
Call Girls In Malegaon !!
Call Girls In Sangli !!
Call Girls In Ulhasnagar !!
Call Girls In Panvel !!
Call Girls In Akola !!
Call Girls In Kolhapur !!
Call Girls In Nanded !!
Call Girls In Dhule !!
Call Girls In Solapur !!
Call Girls In Aurangabad !!
Call Girls In Vasai Virar !!
Call Girls In Kalyan !!
Call Girls In Nashik !!
Call Girls In Pimpri Chinchwad !!
Call Girls In Nagpur !!
Call Girls In Pune !!
Call Girls In Wadala !!
Call Girls In Mahim !!
Call Girls In Gorai !!
Call Girls In Marol !!
Call Girls In Virar !!
Hi, is a true life experience is not designed to convince you its a personal health experience, sometimes medical doctors take a different approach about herpes treatment. i has been stocked in bondage with herpes for two years and four months i has tried different means to eliminate this sickness because it surely has distract me even with the world, and i was told there is no cure, but only medicine for treatment all the possible ways i has tried was treatment, two months back i did some herpes research and i found amazing testimonies concerning natural herbal cure, and i go for it through the email address from the post just to give a try of herbal treatment, and i found it grate without delay i got cured with natural treatment from doc Twaha herbal cure his cure are powerful and shows out excellent result. and i think everyone suffering with herpes and others symptoms should also know about this cure from, drlregbeyen10000@gmail.com or WhatsApp him +2349038518881 thank you
ReplyDeleteYou have performed a great job on this article. It’s very precise and highly qualitative.
ReplyDeleteHere we are providing you the best service of ij start canon printer, if you are facing any kind of problem in printer installation, then you should see our site because the method of printer setup in our site is very simple and explained in steps. You will get the solution to all your problems on our site.
Nice Blog !
ReplyDeleteOur team at QuickBooks Customer Service works under a tight timeline to give you effective service for QuickBooks amid new normal time.
Im grateful for the article post.Much thanks again. Cool.Prime male reviews
ReplyDeleteAthletic greens review
Thanks again for the blog article.
ReplyDeleteconversion ai review
Bioleptin reviews
Major thanks for the article.Thanks Again. Much obliged.
ReplyDeleteGRS Ultra reviews
Ultra Omega Burn reviews
It’s difficult to find experienced people for this subject, however, you seem like you know what you’re talking about! Thanks
ReplyDeleteBest Joint Supplement for knees
Best Testosterone booster for men
Hello There. I found your blog using msn. This is a very well written article.
ReplyDeleteCBD oil near me
Reviews on organifi green juice
I’ll make sure to bookmark it and come back to read more of your useful information. Thanks for the post. I’ll definitely return.|
ReplyDeleteReviews on organifi green juice
organifi green juice
Hi there! This article couldn’t be written any better!
ReplyDeleteLeptoconnect review
Resurge supplement
Looking at this post reminds me of my previous roommate!
ReplyDeleteproven supplement reviews
Synapse XT complaints
He always kept talking about this. I will send this post to him.
ReplyDeleteleptitox reviews
sonus complete review
Superb post but I was wondering if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit more. Kudos!
ReplyDeleteSteel bite pro ingredients
Okinawa flat belly tonic review
Fairly certain he will have a very good read. I appreciate you for sharing!
ReplyDeleteMasszymes reviews
Custom keto diet reviews
Hi there! This post couldn’t be written any better! Reading this post reminds me of my good old room mate! He always kept talking about this. I will forward this write-up to him. Fairly certain he will have a good read. Thank you for sharing!|
ReplyDeleteOrganifi pure reviews
meticore reviews 2021
Efficiently written information. It will be profitable to anybody who utilizes it, counting meCBDfx review
ReplyDeleteTestogen ingredients
google 942
ReplyDeletegoogle 943
google 944
google 945
google 946
Do My Homework for Me?
ReplyDeleteThe Answer is Yes. We at Do My Homework Help are looking for opportunities to help you complete your homework on time so that you do not miss any of your assignment submissions. We are here to help you achieve balance in your life and make you enjoy what you like without worrying about completing your assignments. Our team is well educated and expert in writing different types of assignments and doing homework for all the fields, including commerce, Management, Accounting, Business, Science, Computer Science and many more.
Do My Homework For Me
Do My Homework Help
Most Popular Download Games. Download free full version games for your PC. Minecraft. Let your imagination fly and build your own world.
ReplyDeletemax payne 2 download for pc full version highly compressed
Nice post. Keep sharing this type of post with us. This post gave me a lot of information on this topic. Keep sharing this type of blog with us.
ReplyDeletepush video wallpaper torrent
slimcleaner plus torrent
winx hd video converter deluxe license key
araxis merge torrent
If you are looking for an assignment service in Saudi Arabia then you are at right place. We are into assignment writing service for last 7 years. Our online assignment services includes a team of expert writers who can complete your work in the most authentic and impressive way.
ReplyDeleteThis software is very helpful for as, thanks for sharing Nero Burning Rom Crack
ReplyDeleteAnd Also Visit This Site ProCrackerz
Hey! Lovely blog. Your blog contains all the details and information related to the topic. In case you are a QuickBooks user, here is good news for you. You may encounter any error like QuickBooks Error, visit at QuickBooks Phone Number for quick help.
ReplyDeleteI’m impressed after reading your article titled, How to activate Roku using Roku Error Code 014.12.
ReplyDeleteYou have explained Roku.com/link activation steps clearly. My review rating for the blog post would be 100 Starz. Keep posting more interesting blogs
Let me share the post with new users who do not know how to activate Roku
DriverToolkit Crack Excellent piece of work, and I am in wonder how you manage all of these content and his entry. I would like to say you have superb capabilities related to your work, and lastly, please keep it up because I am looking for the more.
ReplyDeleteAnd Also Visit This Site ProCrackerz
AVG Secure VPN Crack Excellent piece of work, and I am in wonder how you manage all of these content and his entry. I would like to say you have superb capabilities related to your work, and lastly, please keep it up because I am looking for the more.
ReplyDeleteAnd Also Visit This Site ProCrackerz
Do you need an urgent loan of any kind? Loans to liquidate debts or need to loan to improve your business have you been rejected by any other banks and financial institutions? Do you need a loan or a mortgage? This is the place to look, we are here to solve all your financial problems. We borrow money for the public. Need financial help with a bad credit in need of money. To pay for a commercial investment at a reasonable rate of 3%, let me use this method to inform you that we are providing reliable and helpful assistance and we will be ready to lend you. Contact us today by email: daveloganloanfirm@gmail.com Call/Text: +1(501)800-0690 And whatsapp: +1 (501) 214‑1395
ReplyDeleteNEED A LOAN?
Ask Me.
Great article .Good job.Thank you for sharing with us. I also have a solution for govt job seekar to get online free job alert in India. Know more about latest govt jobs in 2021
ReplyDeleteThanks for sharing this great information, i would appreciate if you share this type of information regularly. Birth Right For All
ReplyDeleteNice blog.
ReplyDeleteGlobal pet insurance market is expected to grow with the CAGR of over 10% by 2026.
pubg-crack
ReplyDeleteezvid-for-pc-crack
avg-rescue-usb-crack
presonus-capture-crack
pianoteq-crack
videoproc-crack
replay-radio-crack
replay-music-crack
roland-zenbeats-crack
musicbrainz-picard-crack
ReplyDeleteI like your all post. You have done really good work. Thank you for the information you provide, it helped me a lot. I hope ezvid-for-pc-crack
I want to to thank you for this wonderful read!! I absolutely enjoyed every bit of it.
ReplyDeleteI’ve got you book-marked to look at new things you post…
freeactivationkeys.org
vivaldi-browser-crack
xampp-crack
vpn-unlimited-crack
protonvpn-crack
immunet-crack
wintools-net-premium-crack
android-studio-crack
bootstrap-studio-crack
DO YOU NEED A PERSONAL/BUSINESS/INVESTMENT LOAN? CONTACT US TODAY VIA WhatsApp +19292227023 Email drbenjaminfinance@gmail.com
ReplyDeleteHELLO
Do you find yourself in a bit of trouble with unpaid bills and don’t know which way to go or where to turn? What about finding a reputable Debt Consolidation firm that can assist you in reducing monthly installment so that you will have affordable repayment options as well as room to breathe when it comes to the end of the month and bills need to get paid? Then consider your financial problems over. We Offer LOANS from $3,000.00 Min to $30,000,000.00 Max with a low interest rate of 2% and loan duration of 1 to 35 years to pay back the loan secure and unsecured. Our loans are well insured for maximum security is our priority, Our leading goal is to help you get the services you deserve, Our program is the quickest way to get what you need in a snap. Kindly reduce your payments to ease the strain on your monthly expenses
NO MATTER YOUR CREDIT SCORE. GET YOUR INSTANT LOAN APPROVAL 100% GUARANTEED TODAY VIA WhatsApp:+19292227023 Email: drbenjaminfinance@gmail.com
I have no doubt that you are a prolific writer. The ideas you present here are top-notch. Big thumbs up for you. Whatsapp Image Size Limit
ReplyDeleteFree mobile and PC download games. Thousands of free . Download or play free online! . Here is the Exact Arcade Version of Dig Dug! please visit my sites.
ReplyDeletepcsoftwarehere.com
Good jobs, thanks for this articles. This is really a nice and informative, its very easy to understand for everyone. your way of explanation is amazing. you are doing appreciating work
ReplyDeleteif anyone wants packing and moving services so contact Om international packers in Gurgaon Its very informative article sir, and very easy to understand.
Thank you for posting such a great article. Keep it up mate.
ReplyDeletettms net banking
You are business and using the quickbooks software for financial work like payroll, accounting etc. whenever you face problem Quickbooks won't open, you can use the quickbooks component repair tool for resolve that issue.
ReplyDeleteBrother Printer won't print black
ReplyDeletehttps://mybtmailx.blogspot.com/2021/06/step-by-step-guide-for-icloud-mail-sign.html#comments
ReplyDeleteThanks for sharing this amazing content your information is really very awesome to read. Keep it up and best of luck with your future updates. Check out thinking of you messages for clients
ReplyDeleteBuy online the best price rechargeable international mobile cheap international calls to India to call from the USA, Canada, Australia and UK with the help of amantel.com.
ReplyDeleteI'm really impressed with your writing skills, as smart as the structure of your weblog.
ReplyDeleteDAEMON Tools Pro Crack
ESET NOD32 Antivirus Crack
Yandex Browser Crack
Logic Pro X Crack
Greetings! Very useful advice in this particular post! It is the little
ReplyDeletechanges which will make the biggest changes. Thanks for sharing!
스포츠토토
We are with you when you take the journey of becoming a mother to deliver your new-born. We provide you with care, comfort, and expertise necessary for enjoying the pleasure of parenting. Every birth is unique and every baby is a special gift. We are honoured to be part of this exciting time in your life best maternity hospital in Bangalore.
ReplyDeletebest hospital for normal delivery in bangalore
fertility center in bangalore
The ability to work from anywhere with an internet connection provides me with greater flexibility while traveling, whether it be to visit family, travel to watch my favorite sports on TV. I’m looking for this kind of flexibility.
ReplyDelete섯다
You are always at your best to feed your readers with interesting, thoughtful and educative information, keep doing it, and thank you so very much for a great job always, meanwhile, you can checkout this fuoye departmental cut off mark
ReplyDeleteAre you looking for an immigration lawyer?
ReplyDeleteIf you are an international student or skilled worker.we can help you with your visa application. We have successfully challenged the refusals of all
visa applications including complex applications.Our immigration solicitors are experts in their field and will provide the best possible service
to ensure that your application is successful.legal aid immigration solicitors near me.
You want to work in the UK but need a Tier 2 General Visa? Or perhaps you’re looking for permanent residency status so that you can live and work here
permanently? Whatever it is, our team of expert immigration solicitors will be able to assist! We offer free consultations so why not give us a call today
on 0208 124 3222 or email us at info@immigrationsolicitors4me.co.uk . Let’s get started on making sure your application is successful!
This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great! 카지노사이트
ReplyDeleteI definitely savored every part of it and i also have you bookmarked to check out new things in your web site.Best Non Slip Shoes
ReplyDeleteI want to testify on how I got cured from Herpes. I have been living with this disease for the past 11 months, i have done all i can to cure this disease but all my efforts proved abortive until i met an old friend of mine who told me about a herbal doctor called Dr Oniha, she told me that Dr Oniha have cure for all kinds of diseases, though i never believed in it because my believe was that there is no cure for Herpes disease. But I decided to give it a try when I contacted Dr Oniha, he told me he has a cure for herpes that he cured with herbal medicine. I order for the herbal medicine, which Dr Oniha sent to me through a courier service which i make use of and now behold the herpes is gone and i now have my life back,if you are out there living with this disease i will like you to also contact Dr Oniha and get this disease cured out of your body. I am a living testimony of Dr Oniha herbal cure. Thanks once again Dr Oniha for you are God sent. contact Dr oniha through his contact information.
ReplyDeleteEmail:driyaseherblahoe@gmail.com
Whatsapp number: +2347057052206
HP Printers are among the most popular printers on the market, and they work well with PCs. There is no doubt that 123 hp com setup Printers are a top choice for home users, small offices, and even business customers
ReplyDeleteNiccee blog!I just stumbled upon your blog and wanted to say
ReplyDeletethat I have really enjoyed browsing your blog posts 토토
Epson printers are one of the most advanced printers available today. However, many Epson printer drivers are experiencing problems with their printer. When they try to print anything with their Epson printer, it does not respond to their commands. Thus, you need Epson Printer Troubleshooting as soon as possible.
ReplyDeleteThe full instruction will be seen on your system screen when you enter the link 123.hp.com/setup. The complete guide for solving Printer Not Printing Black issues is introduced on that page. So, open it on your browser and go through the provided instructions one by one. Surely, your printer will start printing correctly in black color.
ReplyDelete123.hp.com.setup
I'm sure you've heard of penis extenders before. They are one of the most popular methods for enlarging your penis - and there's a lot of conflicting information about them! Some people will tell you that they don't work, while others swear by their effectiveness. Do they really work? What do experts say? How can I find out if it will work for me? These are all good questions to ask when considering whether or not to invest in a penis extender. In this blog post we'll discuss: what is a penis extender; how does it work; pros and cons; reviews from customers who have used them; and which ones to buy (so you can make an informed decision). Best Penis Extenders
ReplyDeleteIf you need a loan but have bad credit, then your options are limited. But don't worry! Here is a guide to finding the best bad credit loans for people with less than perfect credit. Bad credit limits what lenders will offer you, so it's important to get creative when looking for financing. Bad credit loan guaranteed approval
Hello everyone! In this blog post, we will be talking about male enhancement and the various ways that you can go about improving your sex life. Male enhancement is a topic that many people find difficult to talk about in detail because it's such a private matter. However, I'm not one of those people! If you're looking for the best pills for your needs, then this article has everything you need to know. We'll discuss six pillars of male enhancement: enhancing blood flow, stimulating hormones, increasing testosterone levels, reducing stress and anxiety levels (which reduce libido), improving erection quality and duration- which all work together to create an overall heightened sexual experience. Best male enhancement pills
ReplyDeleteWhen you have a small penis, it can be really embarrassing. You're too afraid to do anything with your life because of how people are going to react when they find out. It's not fair that men who are well endowed get all the fun while guys like us suffer for something we didn't choose! The good news is that there are options for those of us who want to give our sex lives another chance. Sizegenetics has been around for over 15 years and has helped thousands upon thousands of men finally enjoy their sex lives again. SizeGenetics
Do you have a small penis? If so, this post is for you. Phallosan Forte can help increase your size and give you that feeling of true manhood. In the past, penile extenders were only available to those who had undergone surgery or suffered from some other medical condition. Now there are more options available on the market, including an affordable model like Phallosan Forte which has been proven by many satisfied customers to work as well as a surgical procedure without any of the risks or side effects! Phallosan forte
ReplyDeleteVigRX Plus is a male enhancement supplement that has been on the market for over 10 years. It contains all natural ingredients, which are safe and effective in helping to increase your sexual performance when taken as directed. VigRX Plus Review
I'm going to give you an honest review of Performer8. It's a male enhancement pill that the company claims will increase your stamina, libido, and sexual performance. They also claim it's 100% guaranteed to work or they'll refund your money in full. This sounds like a pretty good deal, but before you try it out for yourself I want to tell you what I found when I researched this product. Performer 8 reviews
ReplyDeleteThere are many male enhancement pills available in the market today. But do they really work? VigRX Plus is one of the most popular choices for men who want to increase their penis size, sexual stamina and performance. VigRX Plus Reviews
Whenever you wish to print a document, you will tap on “Print” and your preferred printer, but nothing occurs. To return your printer status from offline to online, you need to follow this simple guide and you can see this printer offline
ReplyDeleteThe content on this Malwarebytes Crack POST is excellent. You can download crack software for Mac and Windows from CRACKGRID Site.
ReplyDelete
ReplyDeleteThank you for sharing the informmation. Here I want to discuss about assignment help online. TEAMVIEWER CRACK
ReplyDeletewow this websites much more impress me.Shadow Defender [1.5.0.726] Cracked
mediahuman youtube downloader
ReplyDeleteYeomen Warders have been in service at the Tower of London since 1485 when the corps were formed by King Henry VII, although their origins date back even further.
Thank you so much for awesome post! An opportunity to read a superb blogs, I really like to read your article, the points you have mentioned in this article are helpful for me.
ReplyDeleteSecurity Monitor Pro
If Check the two finishes of the USB link are solidly embedded. Assuming the hp printer offline is arranged then ensure the Ethernet link is immovably embedded. If that the printer is remote actually take a look at your web association or ensure it's associated with your switch.
ReplyDeleteA good, simple to install and utilize across the board machine. Modest separate tops off accessible. I like that it doesn't need to sit with paper hanging out, all things considered, the time, and that the conveyance plate opens just when the canon mg3620 is going to work. It doesn't close again without help from anyone else, however, all things considered, it appears to be an extremely affordable, all-around made peaceful, and gorgeous unit.
ReplyDeletevery nice.keep it up good work.HD Tune Pro Crack
ReplyDelete
ReplyDeleteI hope this post is beneficial for viewers. Many thanks for the shared this informative and interesting post with us.
eplan-fluid
Hi dear, It is very enjoyable to visit Your website because you have such an Amazing Writing Style.
ReplyDeleteMany thanks for the shared this informative and Interesting post with us
NoteBurner Spotify Music Converter
Great post,Thanks For Sharing.
ReplyDeleteAbortion Clinic Fort Lauderdale
बड़ा आसान है कंप्यूटर से फेसबुक अकाउंट को डिलीट करना, बस फॉलो करने होंगे ये स्टेप्स Read More
ReplyDeleteNews Website
News website profile
News website comments
Vidrohi aanand
Vidrohi Anand
Anand news
Latest News
Cricket News
Exam News
ReplyDeleteYour post style is super Awesome and unique from others I am visiting the page I like your style.
Havij Pro
https://crackhow4.com/fcpx-auto-tracker-crack/
ReplyDeleteFCPX Auto-Tracker 2.5 Crack + Torrent [2022] Free Download FCPX Auto-Tracker Crack is a tracking tool movement that was designed specifically for Final Cut Pro X.
LiquidText Crack is software that has a modern appearance. It is a simple and easy-to-use tool. Its work process is amazing. It is best for everyone.
ReplyDeletehttps://crackhow4.com/liquidtext-crack/
DbVisualizer Crack is a simple and effective software solution that assists you in managing and maintaining your database with little effort. It is available on CrackHow4.com.
ReplyDeletehttps://crackhow4.com/dbvisualizer-crack-keygen/
https://crackhow4.com/sidify-music-converter-crack/
ReplyDeleteSidify Music Converter 2.4.3 Crack + Serial key [Torrent] Free Download Sidify Music Converter Crack is award-winning and sophisticated software that allows you to get music from Spotify and bypass DRM limitations.
3D Movie Maker Crack + Torrent [2022] Full Download Pc 3D Movie Maker Crack (often abbreviated as 3DMM) is a 1995 Microsoft Kids application.
ReplyDeleteMediGlow Healthcare is one place that tries to put its every effort into being an efficient healthcare system contributing an important part in the country’s development, economy, and promoting the physical and mental health being of people around the world. Healthcare has always been regarded as an integral part of the whole system as the quality of life is very important and helps people all around with different kinds of solutions.
ReplyDeleteExample Services :-
Hair Transplant
Hydra facial
Eyebrow Microblading
Acne, Scar treatment
Hair PRP
Chemical peel
Medical Cosmetology/Aesthetic Physician
General Physician
Thank for sharing this useful information.Need assistance an Epson printer setup, driver install, troubleshooting issues. Feel free to reach our website. Epson Printer Driver
ReplyDeleteWow, amazing block structure! How long
ReplyDeleteHave you written a blog before? Working on a blog seems easy.
The overview of your website is pretty good, not to mention what it does.
In the content!
vstpatch.net
TeamViewer Crack
PGWare GameGain Crack
JixiPix Rip Studio Crack
Airmail Crack
Photopia Director Crack
I would like to thank you for the efforts you had made for writing this awesome article.
ReplyDelete3D industrial rendering