If anyone asked me if I had special plans for Valentine's, I wanted to be able to say "statistics".
So here's another bit of work that I did with a coworker at 23andMe. Using genetic data, you can identify parent-child pairs, and from that you can find "trios" -- a couple and the child they had together. 23andMe's database contains thousands of such trios, which are incredibly useful for studying everything from genetic recombination to inherited disease...to why people reproduce together. Which, it being Valentine's, is what I want to talk about.
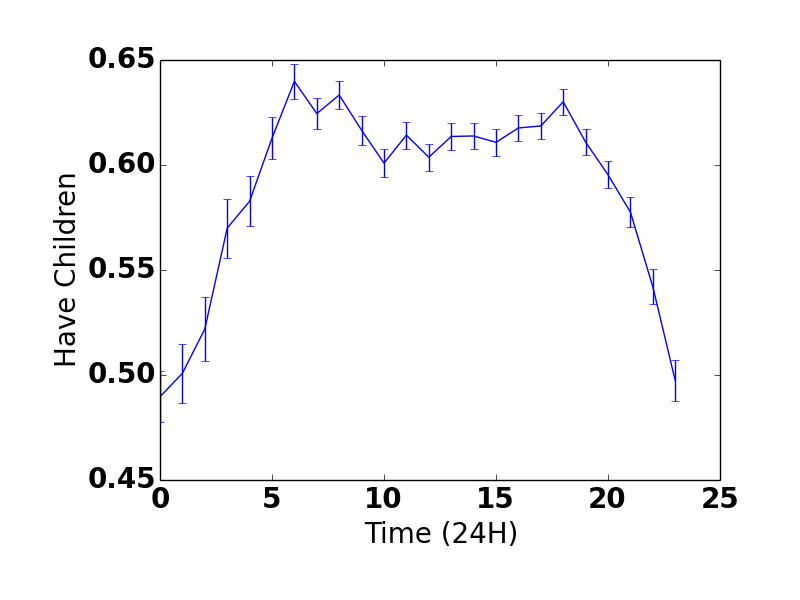
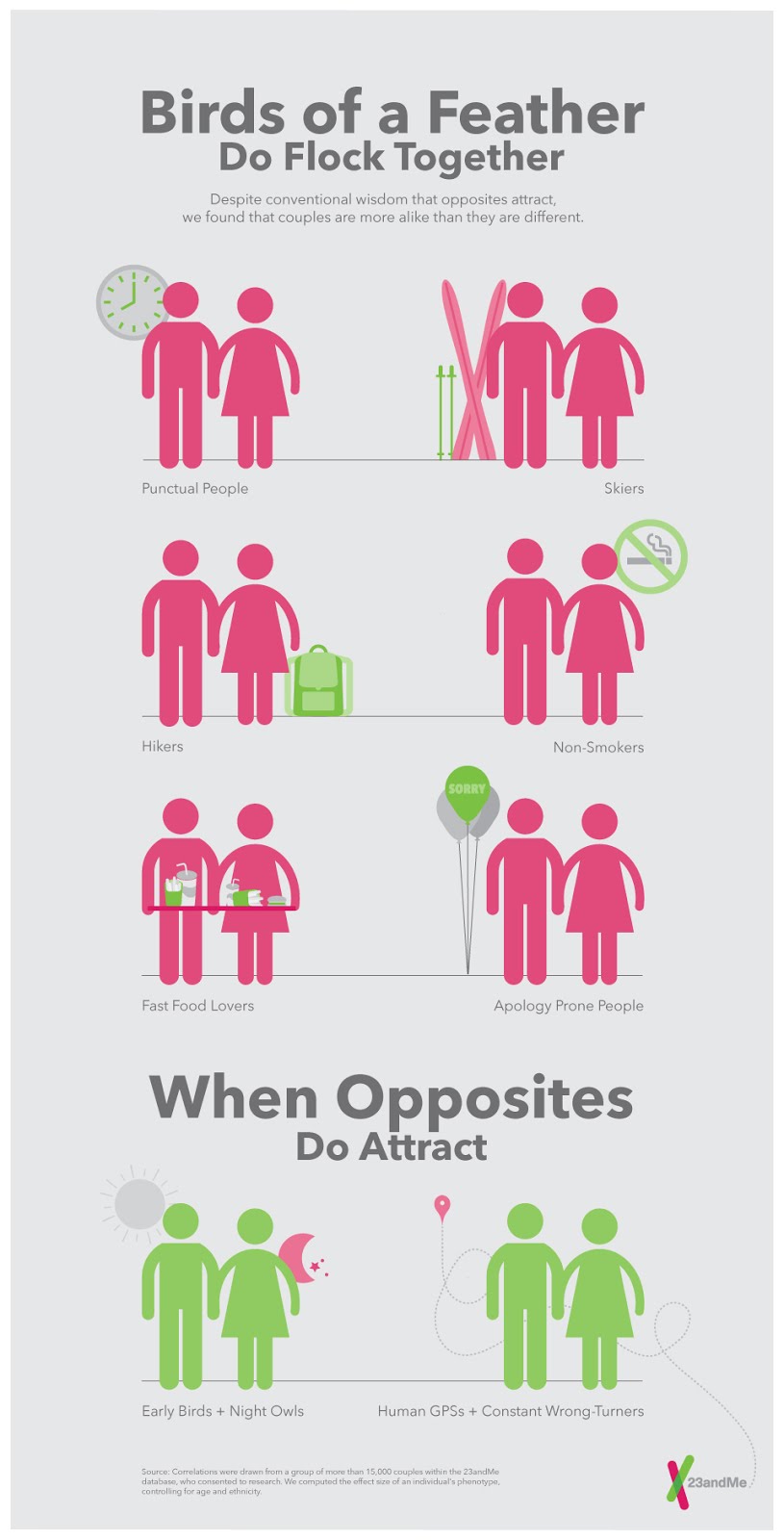
We studied thousands of traits in the trios, and we found that, for about 97% of traits, birds of a feather flock together: your reports for how often you eat drive-through food, how apology prone you are, how punctual you are, are highly correlated with your partner's reports. There are rare exceptions to this -- those with good senses of direction tended to pair with those who lacked one, and morning people tended to pair with night people. (The most famous example of the latter might be Romeo and Juliet: remember when she whines at him to stay in bed -- “It was the nightingale, and not the lark/That pierced the fearful hollow of thine ear”--in spite of the fact that he’s going to DIE?) 23andMe's designers made this beautiful infographic:
But maybe similarity in most traits occurs merely because people of similar age pair together? Whether you have dentures, say, may be highly correlated with whether your partner does, but that’s not because you find matching orthodontia sexy -- it’s just because older people tend to have dentures, and older people tend to pair together. But even when we controlled for similarity in age and race [1], our correlations remained highly significant.
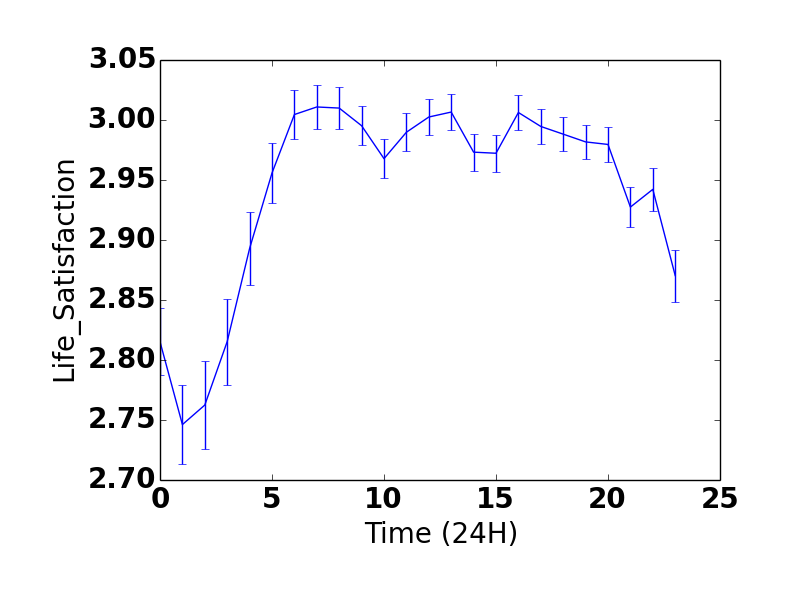
We also checked whether couples with bigger differences in BMI, age, and height tended to report lower life satisfaction, and for age and BMI, they do. (No significant effect for height, which is good, because my dad is a foot taller than my mom.) This isn’t just because if your BMI differs dramatically from your partner’s, it’s a sign that one of you is very skinny or very fat: the negative association remained whether or not we controlled for your BMI and your partner’s BMI.
Does similarity cause couplehood, or couplehood similarity? Maybe your mate is attracted to you because you’re always on time for your dates, and she values punctuality; or maybe you’re initially perpetually late, but when you fall in love she trains you.
Similarly, there are at least three possible explanations for why differences in age and BMI are associated with lower life satisfaction:
1. The straightforward causal one: being with someone much older, younger, skinnier, or fatter makes it harder to do things [2] together, and might make at least one of you insecure, leading to lower life satisfaction.
2. Causality in the other direction: if you’re unsatisfied in your relationship, you don’t do things together (like exercise) and your BMIs diverge. (This doesn’t explain age.)
3. Maybe people usually look for mates similar to themselves in age and BMI, and you only break this social norm if you’re unable to find a mate, which might indicate that you’re less compatible with the person you end up with, or that you have other things going on in your life that make you unhappy. (Thanks to Aaron Kalb for this insight.)
Do all these explanations make reporting correlations a waste of time? I don’t think so, because correlations indicate intriguing directions for more refined surveys or causal experiments. It’s just important to keep correlation and causation unentwined -- unlike yo momma and me.
Happy Valentine's Day to everyone, especially Nat, who is (fortunately) not similar to me at all.
Notes:
[1] We actually did this two different ways. We regressed the value of your trait on the value of your partner’s, including in the regression your age and race; the first coefficient remained significant. We also created 15,000 “fake couples” -- a random man and woman -- combined them with the real couples to create a dataset with 30,000 points. Then we regressed whether you were a real couple (a binary variable) on how much you differed in a trait, and included how different you were in race and sex: the first coefficient remained significant. The first method is probably more intuitive, but both agreed.
[2] What things? Heh heh heh.