Friday, July 18, 2014
Plenty of Fish in the Thousand Sampled Seas: Approximating the Probability Someone Likes You
This is another post with fancy visualizations, see here.
Monday, July 14, 2014
A Tale of Two Cities: The Twitter Reaction to the Return of Lebron James
At 9:31 AM PST on July 11, LeBron James announced that he was returning to Cleveland, and Twitter exploded. (If you don’t know who LeBron James is, see [1] for backstory.) The frenzy was such that the New York Times ran a front page story purely about the tweets. I collected more than 2 million of them, and learned some things about forgiveness, race, and fangirls.
One obvious question: did people on balance approve of James’ decision? The NYT did not attempt to figure this out -- come on, NYT! -- probably because they didn’t have the data and it’s hard to measure approval. One standard way to do it is to count words with positive and negative associations using a word list, but this is a bit dicey in this data; words like “fan” are usually positive, but here you have tweets like “LeBron fans suck”. Instead, I came up with customized phrases. For example, I recorded 1,392 tweets containing the phrase “I love LeBron” and 1,549 tweets containing the phrase “I hate LeBron”. But the latter group contained tweets like “Do I hate LeBron still? Nope” -- some people might loathe James for his prior mistakes, but admire this decision. Indeed, the data supports this idea:
Phrase Pair
|
Number of Tweets
|
“good decision” compared to “bad decision”
|
547 to 94
|
“good move” compared to “bad move”
|
954 to 123
|
“smart move” compared to “stupid move”
|
390 to 20
|
Overall, the Twitter data indicates that while James is still polarizing, this decision was popular. Obviously, however, not everyone was thrilled. I recorded 25k tweets from Tweeters who listed “Miami” in their location and compared those to the 21k tweets from Tweeters in Cleveland. This was a little sad. Miami fans used twice as many words expressing negative emotion, three times as many words expressing anger, twice as much profanity. Interestingly, though, they were about four times as likely to express respect: they were sad and angry but also reluctantly impressed. We can also look at the hashtags which were particularly common in each city: some of them were obvious (191/191 “northeastohio” hashtags were from Cleveland) but some were interesting:
Miami Hashtags
|
Fraction From Miami
|
Cleveland Hashtags
|
Fraction from Cleveland
|
goodluck
|
15/15
|
forgiveness
|
14/14
|
neverforget
|
11/11
|
happydaysforthecityistillcallhome
|
48/48
|
lebronliquidation
|
28/28
|
cosmic
|
17/17
|
thankyoulebron
|
98/102
|
cavsgoodkarma
|
87/87
|
notcool
|
179/193
|
welcomehomelebron
|
219/224
|
smh (“shake my head”)
|
12/12
|
unfinishedbusiness
|
20/21
|
tfm (“total frat move”)
|
13/19
|
lifttheban
|
56/61
|
respect
|
49/60
|
imsorry
|
53/58
|
(“Lift the ban” and “I’m sorry” turn out to relate to this crazy Cleveland fan who got himself banned from Cleveland games for a year for running onto the basketball court while James was playing and begging him to return. James patted him on the head as he was dragged away by security.)
Let’s talk about race. Twitter doesn’t provide race data, but I wanted to see if I could infer it for a few reasons:
1. Racial dynamics in professional basketball are often interesting: 76% of the players are black, as compared to 43% of coaches and 2% of owners. There have been a lot of race-related episodes: see the owner who was banned for life for racist remarks; Jesse Jackson’s allegations that Lebron James was being treated like a runaway slave; the differential popularity of Lebron James among different races; the racism against Jeremy Lin.
2. I’ve done a fair bit of work on gender dynamics, and women and racial minorities share many problems; studying race seems a natural extension.
3. It’s an interesting problem.
Obviously, race is very complicated -- at 23andMe, I’ve learned from our ancestry experts just how tangled the relationship between biological ancestry and self-identified race is -- and so any inference from Twitter data is going to be highly imperfect. Please keep this in mind before writing me blistering emails. I tried to identify Tweeters as black, white, Hispanic, or Asian, and used three methods to do so:
1. Tweeter self-description. Someone who uses the word “Asian” in their self-description is usually Asian, although obviously there are some false positives (people who use the word black but are saying they like black dresses, etc).
2. Tweeter last name. See here. This turns out to be very useful for Asian and Hispanic names, not so much for white vs black names.
3. Tweeter first name. Freyer and Levitt wrote a nice article about the consequences of having a distinctively black name; we can supplement their list of black and white names with data on baby names from NYC, which gives us Asian and Hispanic names as well.
People have been trying to get race from name for many years and it’s a lot more dicey than getting gender from name. The most basic problem is this: while someone who names their kid “Alabaster Snowflake” is probably white, they’re also probably not representative of the general white population. The people for whom you can identify race from name are going to be unusual. Similarly, someone who identifies herself as Asian on her Twitter profile may not be representative of Asians generally. So we’re not really comparing white people to Asian people, we’re comparing people with distinctively white names to people with distinctively Asian names [2]; similarly for profiles. To emphasize this distinction, I'm going to refer to tweeters not as "Asian" but as "d-Asian" -- ie, distinctively Asian.
I was able to identify 124k tweets from d-White tweeters, 32k from d-Hispanic tweeters, 12k from d-black tweeters, and 7k from d-Asian tweeters (in North America). I could not identify clear racial differences in whether Tweeters approved of James’ decision, but I found other interesting differences. d-Asian tweeters do, in fact, tend to tweet about Jeremy Lin; 56% of tweets containing “jlin” come from d-Asians. d-Hispanic tweeters are especially likely to use hashtags supporting teams in Los Angeles, San Antonio, and Miami -- all cities with large Hispanic populations -- and, unsurprisingly, tend to use Spanish words. d-black tweeters also tended to use different language: “finna”, “ima”, “tryna”, and “yall” were among the words that increased in frequency most among d-black Tweeters, as were various versions of n*****. (d-Black tweeters were about four times as likely as d-white tweeters to use n***a, with d-Asians and d-Hispanics falling in the middle.)
I also looked at gender. Only about 17% of tweets came from women, and some of the male tweeters complained about how female tweeters were just tweeting “I looooove LeBron!” But the stereotype of the sweet-spoken fangirls turns out to be wrong: the girls tweeting about James express more anger and use more profanity than the guys, and while they are indeed more likely to say they love him, they’re more likely to say they hate him, too. And forget about the welcoming female domestic stereotype: female tweeters are actually slightly (but statistically significantly) less likely to use variants of “welcome home”. These results surprised me enough that I checked whether my filters were broken (I don’t think they are); one explanation is that interest in basketball is somewhat unusual for women, and that women who tweet about LeBron James are unusual in other ways as well. (Alternately, there might be some weird correlation between gender and another variable, like location.)
This is about as much time as I'm willing to spend studying LeBron James; on the other hand, if you could infer race in a way that doesn't introduce weird biases, that would be exciting and powerful, so let me know if you have ideas about that. Also, I realize that race (like gender) is a fraught topic, so please let me know if anything I've written seems insensitive or inaccurate.
This is about as much time as I'm willing to spend studying LeBron James; on the other hand, if you could infer race in a way that doesn't introduce weird biases, that would be exciting and powerful, so let me know if you have ideas about that. Also, I realize that race (like gender) is a fraught topic, so please let me know if anything I've written seems insensitive or inaccurate.
Notes:
[1] LeBron James is one of the greatest and most polarizing basketball players of all time. At 18, he began his career playing for Cleveland, a sad sports city that hasn’t won a championship since 1964; then he broke their hearts and drew widespread disgust by announcing in a graceless press conference that he was leaving to join two superstars on Miami’s team.
[2] I initially thought I could get around this problem by looking at all names and simply assigning each name a score for each race depending on how frequently it was used for that race (rather than just looking at names with >90% confidence for a particular race); this would incorporate data for all Tweeters rather than just the distinctive name ones, and then you could just run a regression on the name race score. I think this runs into a similar problem, though, because you find that for black last names, for example, very few Tweeters have names which strongly indicate that they are black, which may mean that whatever signal you get is predominantly driven by these distinctive Tweeters.
Tuesday, July 8, 2014
From Kale to Cancer: Using Multiple Datasets to Kill Bias
I work just down the block from Google, and I get the sense that it’s devouring me: every time I drive home I’m surrounded by rainbow Google bikes, giant Google buses, Google Street View cars, Google self-driving cars. But I still haven’t managed to get what I actually want: their data.
Recently, however, I found a way to combine the 23andMe and Google datasets and thus achieve absolute power increase my faith in 23andMe’s dataset. We describe the work on 23andMe’s blog here. It relies on a tool called Google Correlate, which was used, among other things, to build Google Flu Trends: basically, Google Correlate lets you enter a number for every state and see which search terms show the strongest correlation with that state-by-state pattern. For example, when I enter the average latitude for each state, I see that the search terms which are most frequent in Northern states are those you would expect: “how much vitamin D”, “heated seats”, “seasonal affective disorder”, etc.
You can do this with 23andMe data: we know where many of our customers live, and we have their answers to thousands of survey questions, and this allowed me to make maps for more than 1,500 health and behavioral traits. I put the data behind those maps into Google Correlate. I started with 23andMe customer answers to “How often do you eat leafy greens?”, and out of the billions of Google searches, one of the most strongly associated was “raw kale”. States with high rates of 23andMe customers with coronary artery disease also had high rates of Google searches for “statin drugs”, which lower cholesterol. Just as striking were the negative correlations.
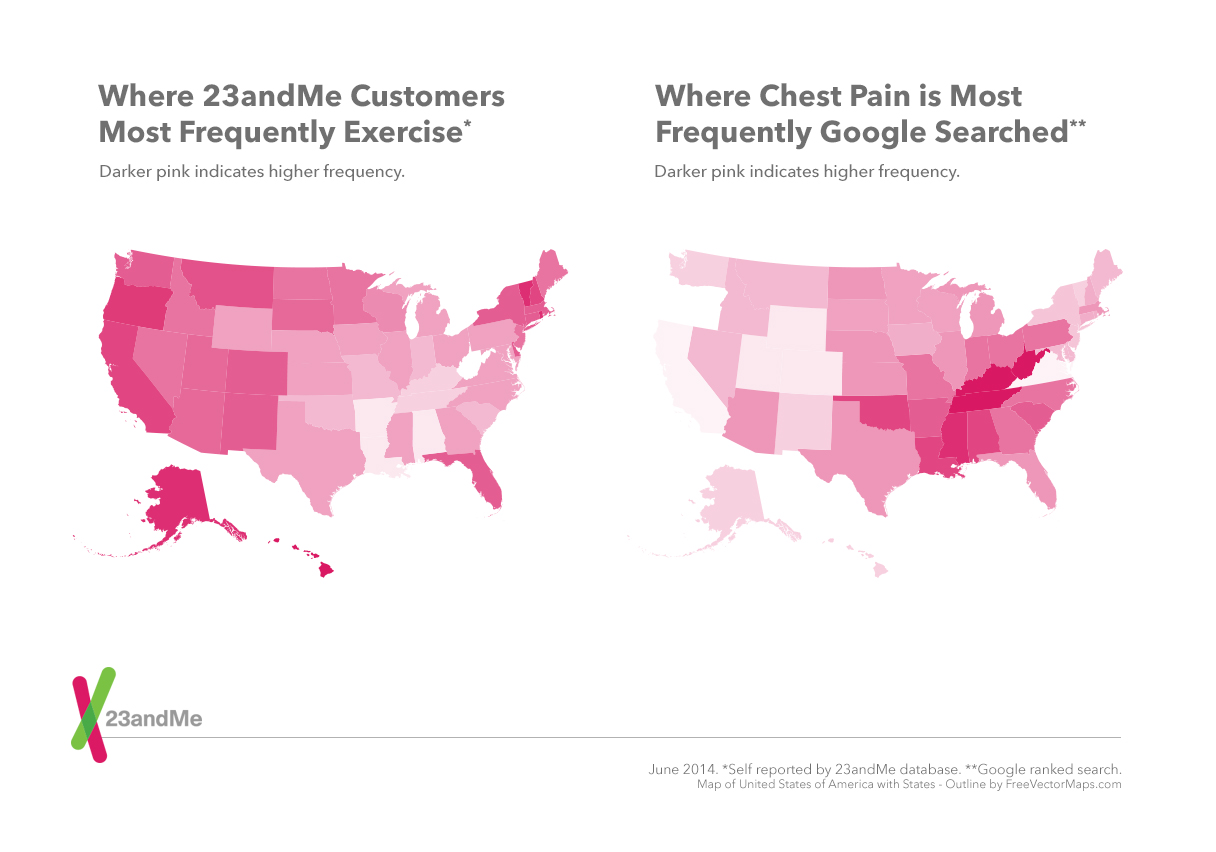
The inverse pattern is clear (and highly statistically significant, even after multiple hypothesis correction). These connections are fun and surprising, given the billions of Google searches, the thousands of 23andMe traits, and the fact that typing in a Google query is very different than answering a medical survey. But I want to talk about a larger point here, which is how we can combine multiple datasets to overcome bias, the specter that haunts my data-related dreams.
By bias I mean “something that makes the number you’re estimating different from the number you want to estimate, no matter how much data you get”. Let’s say you’re trying to figure out whether there’s a difference in physical attractiveness between chessplayers and non-chessplayers. (Yes.) So you go on a dating website with a lot of chessplayers (checkmates.com) and you download all the pictures and you write an algorithm which evaluates the attractiveness of a picture and you compare the algorithm’s output for chessplayers and non-chessplayers. You find that your algorithm says that chessplayers are on average 15% more attractive. You should immediately worry about two things. First, is that difference statistically significant? If you only looked at 4 chessplayers, and one guy was egregiously ugly, it’s probably not. But statistical significance is usually the easy problem, because it can be solved by getting more data; that’s hard if you’re trying to recruit, say, people with a rare psychiatric condition, but I work with datasets which are large enough that statistical significance is rarely an issue. Any difference large enough to care about has like a chance in a trillion of being due to chance.
But bias is a much more insidious problem, because it cannot be solved by getting more data. Here are some biases we might see in the chessplayer problem:
a) Maybe chessplayers who post photos online are more attractive than the average chessplayer.
b) Maybe chessplayers who engage in online dating at all are more attractive than the average chessplayer.
c) An algorithm that measures attractiveness? Really? I’m not a computer vision expert, but I’d be immediately worried that the algorithm was being biased by differences that had nothing to do with the faces. Maybe chessplayers tend to pose with chessboards, and that creates a tiny discrepancy in how the algorithm evaluates them.
In all of these cases, bias means that what you’re trying to measure -- the difference in attractiveness between chessplayers and non-chessplayers in the general population -- is not what you’re actually measuring. More data will not fix bias, because you’ll always be measuring the wrong thing.
We can think of these two problems -- statistical significance and bias -- in terms of romantic pursuits. A statistical significance problem is like when you ask someone out and they say, “I’m sorry, but I just don’t know you well enough yet” -- they need more data. But a bias problem is when they say, “I’m sorry, but I just don’t like you” -- no matter how much more of you they get, you’re still not going to be what they want [1].
I’m now being accused of being frivolous, so here are two more important examples. Why do we care about low voter turnout? It isn’t because we don’t have enough votes to detect a statistically significant difference between candidates. Even in a very close election -- 51 - 49, say, which even in the 2000 presidential race occurred in only 6 states -- the difference will be statistically significant (p < .05) even if only 10,000 people turn out to vote. We worry about low voter turnout because it often produces bias: those who vote have higher incomes, are better educated, are less likely to be minorities, etc. (There are rare cases where the election is so close that the difference actually isn’t statistically significant -- not to start a flame war, but in Florida in 2000, Bush would’ve had to win by about 5,000 votes, not the 537 he actually won by. Even then we might’ve worried about bias due to irregularities in the election process -- but luckily we can all sleep soundly thanks to the completely non-partisan Supreme Court decision.) I think if you actually wanted to measure who the country really wants to be in charge, you would just contact a small randomized sample of people in each state and not let anyone else vote; that would better deal with the bias problem.
Let’s take an example which is less likely to get me mean emails: developing a blood test to detect cancer while it’s still treatable. A lot of people have tried to do this, and pretty much the same thing always happens: they write a paper saying that you can detect cancer X by looking at the levels of molecule Y, everyone gets excited, other people try to replicate the results and they never can. The most plausible reason for this is that the original results were due to bias. What you want is a blood test that can tell the difference between apparently healthy people who secretly have cancer and apparently healthy people without cancer. But apparently healthy people who secretly have cancer are hard to find, because most cancers are rare, so you would have to take blood from a lot of healthy people -- hundreds of thousands, in some cases. So most scientists use a shortcut: rather than taking blood from apparently healthy people with cancer, they just take blood from people with cancer. Those people are easy to find: you just go to a hospital. Unfortunately, this means you haven’t designed a blood test that can detect cancer in apparently healthy people -- you’ve designed a blood test that can detect cancer in people we already know have cancer at your particular hospital. Which is fine, if these two groups have the same blood -- but often they don’t. For example, cancer treatment itself messes with your blood -- blood samples may be collected while the patient is under anesthesia, or undergoing chemotherapy, which both alter your blood. So you haven’t created a cancer detector; you’ve created a chemotherapy detector. Or maybe your cancer and healthy populations are different for reasons you don’t care about -- one attempt to develop a screen for prostate cancer compared cancer patients (who were all men) to healthy controls (who were all women). So then you’ve created a sex detector.
Summary: bias undermines democracy and kills people. What do we do about it? There are standard practices for reducing bias -- controlling for obvious things like sex, doing double-blind studies so your results aren’t influenced by what you want to see. But I still tend to be very nervous about bias, in part because I’m a nervous person and in part because everything is intercorrelated, so tiny discrepancies in variables you don’t care about can produce discrepancies in variables you do. Another powerful means of determining whether a pattern is due to bias is to see if you see the pattern in a very different dataset. Because while both datasets likely have biases, they’re unlikely to be the same biases: so if you see the same pattern in both, it’s more likely to be due to something real. To return to 23andMe and Google, 23andMe survey results are probably biased by the fact that 23andMe customers aren’t necessarily a representative sample of the general population. Google is going to suffer less from this, since its product is more pervasive, but might be biased by the fact that Google searches map only weakly onto what someone is actually thinking. (For example, if more people Google “I want to have sex with sheep” than “I want to have sex with my girlfriend”, that might not be because more people want to have sex with sheep than with their girlfriend; it might be because they’re freaked out about the sheep, and turn to Google.) Both datasets are going to be biased by the fact that you have to be able to use a computer to use Google or enter 23andMe survey answers, but this is a considerably less scary bias than the ones in the independent analyses.
Obviously, the 23andMe/Google analysis is more of a fun proof-of-concept than a rigorous statistical analysis, but the compare-multiple-datasets idea is an important one. To return to biomedical research: often preliminary analysis will be done on a sample from one hospital, and the results will then be checked on a sample from another hospital; this controls for hospital-specific biases. Or you might do analysis on a dataset of a completely different nature: here’s a lovely analysis that starts by looking at gene expression data over time, draws some conclusions, then investigates whether those conclusions are true by actually knocking out some of the genes and analyzing that dataset as well, and compares these results to another dataset that used another method to analyze the genes.
I’m not saying that every study that uses a single dataset is biased or unpublishable -- clearly that isn’t true. But attempting to replicate results in a different dataset is almost always worthwhile, because anticipating every bias is impossible. This is particularly true if you’re generically curious, like I am, and you’re often poking your nose into fields in which you have no business or background knowledge.
Notes:
[1] In practice, I suspect many people who say the former actually mean the latter, but that is not applicable to our analogy.
Wednesday, July 2, 2014
Who Wanted America To Lose?
To answer this question, I monitored Twitter during the US-Belgium soccer game, tracking a diverse set of hashtags [1] that included everything from the normal (“worldcup”, “usavbel”) to the strange (“waffles”, “murca”). I collected more than 2 million tweets: at peak, more than 10,000 tweets a minute. (For a sense of how much traffic that is: there were more Tweets in one minute about the game than Tweets involving any kind of alcohol name in three hours. It was enough that Twitter began limiting the number of Tweets I could collect, so it’s an underestimate.)
So who wanted America to lose? One way to answer this question is to look at how often tweeters say “USA” vs “BEL” or “Belgium” during the game. While not every tweeter who mentions a country will be rooting for it, of course, systematic disparities are indicative:
Timezones with most USAs
|
“USAs” for every “BEL” or “Belgium”
|
Timezones with Least USAs
|
“BEL” or “Belgium”s for every “USA”
|
America/Detroit
|
8.4
|
Europe/Brussels
|
3.7
|
America/Indianapolis
|
4.4
|
Europe/Skopje
|
2.4
|
America/Halifax
|
4.0
|
Europe/Ljubljana
|
1.3
|
America/New York
|
3.9
|
Europe/Lisbon
|
1.2
|
America/Phoenix
|
3.8
|
Asia/Kuala Lumpur
|
1.1
|
One thing that emerges, besides the obvious geographic trend, is that the people chanting “USA” are more enthusiastic than the people chanting “Belgium”: the ratios are more extreme. This will not be surprising to anyone who watched the game with a bunch of Americans who were drinking, as I did (well, they were drinking. I was writing code.) The most “USA”s in a single tweet: 35. Most theoretically possible, with spaces, given Twitter’s 140 character limit: 35.
Also, in 82/88 timezones, the number of “USA”s exceeds the number of “Belgium”s or “Bel”s combined, and that’s without counting “America”, “Murca”, or “Merica”. So it’s tempting to declare Twitter victory -- but this is premature, given the biases in this dataset. As an American, I’m not intimately familiar with all the hashtags Belgian fans use to describe themselves, some of which may not be in English: this will bias the selection in favor of America fans.
A second way to see the Europe-America rivalry is to look at when people on each continent shouted “Goo...al” with more than one “o” -- on the assumption that people who do that are either a) television announcers or b) happy their team scored. In Europe, these shouts spike after the first two goals, which Belgium scored; in America, they spike after the third, which America scored.
Of course, you don’t need big data to figure out that Belgium wanted America to lose, and I don’t want to go all the way to Brussels to get revenge. Can we use Twitter to pick out more local Belgium fans? I filtered for Tweeters in North American timezones, then looked at Tweeter profile words that were associated with the most “Belgium”/”Bel” tweets relative to “USA” tweets. The top word was “Ronaldo”, either indicating people seeking revenge for Portugal or people who care about soccer independent from the World Cup and don’t just want an excuse to drink and shout about America. (Not that there's anything wrong with that.) Substantiating the second hypothesis, the second word was “chelseafc”, an abbreviation of “Chelsea Football Club”. Also near the top were “canada” and “canadian”, on which I have no comment. None of these phrases were associated with a strong bias in favor of Belgium, though -- the split was about 50-50 -- probably because most people in America don’t want to publicly support Belgium. The most strongly biased American word was “txst”, indicating tweeters affiliated with Texas State University: 98% of their tweets had more “USA”s than “Bel” or “Belgium”s. This was followed by “dawgs” -- mostly University of Georgia fans -- and “offer” -- mostly local businesses, who probably decided that tweeting for Belgium would not be profitable. (One could also try filtering for North Americans who shouted “Gooal” after Belgian goals but not after American ones: unfortunately, this yielded too small a sample to draw conclusions.)
We can also look at how people’s moods changed over the course of the game, using a technique called sentiment analysis that looks for positive or negative words (this is what was used in the recent Facebook study). For example, a large number of Americans tweeted about waffles during the game, probably because that is one of the few things Americans can associate with Belgium. But near the end of the game, the tweets involving waffles get both negative and profane. I was disappointed that we lost, of course, but this still seems unfair to me. What did the waffles do to you?
This is obviously just a first look at the data -- I wanted to do a quick analysis while everyone was still excited about soccer -- so let me know if there are things which seem off to you or if there are things you'd like me to look further at! Thanks to everyone who suggested tweets to follow.
Notes:
[1] The full list: worldcup, usavbel, letsdothis, ibelievethatwewillwin, usa,belgian,belgiumfacts,ibelieve,areyouready,onenationoneteam,belgium,bel,merica,murica, king_leopold, Stellartois, saynotoracism, ibelievethatwewilllose, waffles, belgianwaffles,1n1t,usmnt. Some of these -- Stellartois, for example -- were just on the list because I thought they might be interesting, and accounted for a very small fraction of tweets.
Subscribe to:
Posts (Atom)